Multi Pseudo-Calibration (MPC): A Robust Drift Compensation Framework for Sensor Arrays in Biomedical Monitoring
This article explores the Multi Pseudo-Calibration (MPC) approach, a novel strategy for compensating time-dependent drift in sensor arrays used for continuous biomedical monitoring.
Multi Pseudo-Calibration (MPC): A Robust Drift Compensation Framework for Sensor Arrays in Biomedical Monitoring
Abstract
This article explores the Multi Pseudo-Calibration (MPC) approach, a novel strategy for compensating time-dependent drift in sensor arrays used for continuous biomedical monitoring. Tailored for researchers, scientists, and drug development professionals, this work addresses a critical challenge in long-term, uninterrupted bioprocess and physiological monitoring. We cover the foundational principles of MPC, its methodological implementation on platforms like hydrogel-based magneto-resistive sensor arrays, and its integration with regression models such as PLS, XGB, and MLPs. The scope extends to troubleshooting common issues like sensor cross-sensitivity, optimizing performance through data augmentation, and a comparative validation against established methods like the Drift Correction Autoencoder (DCAE). By synthesizing recent research, this article provides a comprehensive guide for deploying MPC to enhance the accuracy and reliability of sensor data in complex, real-world biomedical applications.
Understanding Sensor Drift and the Multi Pseudo-Calibration (MPC) Paradigm
The Critical Challenge of Sensor Drift in Continuous Biomedical Monitoring
Sensor drift, the gradual and often unpredictable deviation of a sensor's output from its true calibrated baseline over time, represents one of the most significant challenges in continuous biomedical monitoring systems [1] [2]. This phenomenon is particularly problematic in biomedical applications where high-fidelity data is essential for clinical decision-making, drug development research, and long-term patient monitoring. Drift can manifest as a gradual shift in baseline (offset drift) or a change in sensor sensitivity (gain drift), both of which compromise data integrity and can lead to erroneous interpretations of physiological parameters [3] [4].
The critical impact of sensor drift is magnified in implanted or intravascular biosensors, where direct physical access for recalibration is limited or nonexistent [4]. For instance, in continuous glucose monitoring for diabetes management or real-time tracking of cardiovascular parameters, undetected drift can directly impact therapeutic decisions and patient outcomes [4]. Similarly, in pharmaceutical development, drifted sensor data from bioreactors can compromise the accuracy of metabolic studies and process optimization, potentially delaying drug development timelines [3]. Understanding, quantifying, and compensating for sensor drift is therefore not merely a technical exercise but a fundamental requirement for reliable biomedical monitoring systems.
Sensor drift in biomedical environments arises from multiple interrelated factors. Aging-related drift occurs as sensor components degrade over time, while temperature-induced drift results from thermal fluctuations in the physiological environment [1]. Chemical drift is particularly relevant for biosensors exposed to complex biological matrices (e.g., blood, interstitial fluid), where biofouling, protein adsorption, and enzymatic degradation can alter sensor characteristics [1] [4]. Additionally, mechanical drift may affect sensors with moving parts or those subject to physiological stresses [1].
The table below categorizes the primary types of sensor drift and their characteristics in biomedical monitoring contexts.
Table 1: Classification of Sensor Drift in Biomedical Monitoring Systems
| Drift Type | Primary Causes | Impact on Sensor Signal | Commonly Affected Sensors |
|---|---|---|---|
| Aging-Related Drift | Material degradation, component aging | Slow, often monotonic change in baseline or sensitivity | All long-term implantable sensors [1] |
| Temperature-Induced Drift | Changes in body temperature or local environment | Changes in offset and/or gain, often reversible | Electrochemical sensors, thermal sensors [1] |
| Chemical Drift | Biofouling, protein adsorption, enzyme inactivation | Altered sensitivity, reduced response dynamics, signal attenuation | Intravascular biosensors, enzyme-based sensors [1] [4] |
| Mechanical Drift | Stress, encapsulation, material fatigue | Hysteresis, baseline instability | Pressure sensors, flow sensors [1] |
The Multi Pseudo-Calibration (MPC) Approach
The Multi Pseudo-Calibration (MPC) approach presents a novel strategy for drift compensation specifically designed for applications where traditional recalibration using external references is impractical [3]. This method is particularly valuable for deeply-embedded chemical sensor arrays, such as those in bioreactors or implantable devices, where interruption for calibration is not feasible [3].
Core Principles of MPC
The MPC framework operates on the principle that periodic samples with known ground-truth concentrations (obtained via offline analysis) can serve as "pseudo-calibration" points [3]. Rather than discarding historical data, the MPC approach aggregates all previous sensor measurements and leverages these pseudo-calibration points as additional input features for a regression model. The model's input vector is constructed by concatenating several key pieces of information: the difference between current sensor readings and historical pseudo-calibration measurements, the ground-truth concentration of the pseudo-calibration sample, and the time elapsed since that pseudo-calibration was obtained [3]. This input structure enables the model to learn and compensate for non-linear drift patterns over time.
Key Advantages of the MPC Framework
The MPC methodology offers three distinct advantages over conventional drift-compensation techniques. First, it can learn complex, non-linear models of sensor drift without requiring pre-defined assumptions about the drift characteristics [3]. Second, it quadratically increases the effective training data; with N training samples, pairing each sample with all previous samples creates an augmented training set with N(N-1)/2 data points, significantly enhancing model robustness [3]. Third, when multiple pseudo-calibration samples are available, MPC can generate and average predictions relative to each reference point, thereby reducing prediction variance and improving overall reliability without interrupting the continuous monitoring process [3].
Experimental Workflow for MPC Implementation
The following diagram illustrates the sequential workflow for implementing the Multi Pseudo-Calibration approach in a continuous monitoring system.
Advanced Drift Compensation Techniques
While MPC provides a powerful framework, several complementary advanced techniques have emerged for handling sensor drift, particularly leveraging recent advances in artificial intelligence and machine learning.
AI and Machine Learning Approaches
Deep learning architectures have shown remarkable success in modeling complex temporal drift patterns. The Incremental Domain-Adversarial Network (IDAN) integrates domain-adversarial learning with an incremental adaptation mechanism to handle temporal variations in sensor data, effectively aligning data distributions across different time periods to combat drift [2]. Similarly, Temporal Convolutional Neural Networks (TCNNs) employing causal convolutions have demonstrated effective real-time drift compensation while being lightweight enough for embedded deployment [5]. These models can be enhanced with spectral transformations, such as the Hadamard transform, which decorrelates sensor signals and separates slow drift components from faster-varying physiological signals [5].
Ensemble methods combine multiple models or sensor readings to produce more robust predictions. The iterative random forest algorithm leverages collective data from multiple sensor channels to identify and correct abnormal sensor responses in real time, providing a powerful approach for fault-tolerant systems [2].
Integrated Drift Compensation Framework
A comprehensive strategy for managing sensor drift in biomedical monitoring systems often combines multiple techniques. The following diagram illustrates how these components work together within an integrated framework.
Experimental Protocols and Methodologies
Protocol 1: Evaluating MPC Performance with Sensor Arrays
This protocol outlines the procedure for validating the Multi Pseudo-Calibration approach using a chemical sensor array, as described in foundational MPC research [3].
Objective: To evaluate the efficacy of MPC in compensating for time-dependent drift in cross-sensitive chemical sensor arrays deployed for continuous monitoring.
Materials and Equipment: Table 2: Research Reagent Solutions and Essential Materials for MPC Evaluation
| Item | Function/Application | Specifications |
|---|---|---|
| Hydrogel-based Magneto-resistive Sensor Array | Primary sensing element for analyte detection | Cross-sensitive sensors capable of detecting multiple analytes [3] |
| Bioreactor System | Continuous monitoring environment | Provides biologically relevant conditions for testing [3] |
| Offline Analyzer | Ground truth measurement | Reference method for obtaining accurate analyte concentrations (e.g., HPLC, mass spectrometry) [3] |
| Regression Algorithms (PLS, XGB, MLP) | Drift compensation modeling | Implemented in Python/R with appropriate libraries (scikit-learn, XGBoost, PyTorch/TensorFlow) [3] |
Procedure:
- Sensor Array Deployment: Deploy the cross-sensitive sensor array within the bioreactor system for continuous monitoring of target analytes.
- Pseudo-Calibration Sampling: Periodically extract samples from the bioreactor at predetermined intervals (e.g., every 24-72 hours) for offline analysis using the reference analyzer.
- Data Collection: Record sensor array measurements with precise timestamps alongside the corresponding ground-truth concentrations from offline analysis.
- Model Training: Implement the MPC approach by:
- Storing all historical sensor measurements and their corresponding ground truths.
- Constructing input vectors that concatenate: (a) the difference between current sensor readings and historical pseudo-calibration measurements, (b) the ground-truth concentration of the pseudo-calibration sample, and (c) the time difference.
- Training regression models (PLS, XGB, or MLP) using the augmented dataset.
- Performance Evaluation: Assess model performance using leave-one-probe-out cross-validation. Divide the dataset chronologically, using the first 75% of measurements for training and the last 25% for testing to evaluate drift compensation effectiveness.
Validation Metrics: Calculate the Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) between model predictions and ground truth measurements. Compare MPC performance against baseline models without drift compensation and against state-of-the-art methods like Drift Correction Autoencoders (DCAE) [3].
Protocol 2: Real-Time Drift Compensation with TinyML
This protocol describes the implementation of a lightweight drift compensation model for resource-constrained embedded medical devices, based on recent advances in TinyML [5].
Objective: To implement and validate a real-time, on-device drift compensation algorithm for biomedical sensors using quantized neural networks.
Materials and Equipment:
- Low-power microcontroller unit (e.g., ARM Cortex-M series)
- Target gas sensor (e.g., catalytic CMOS-SOI-MEMS sensor)
- Data acquisition system with ADC (16-bit recommended)
- TensorFlow Lite Micro or similar TinyML framework
Procedure:
- Data Acquisition: Collect long-term sensor data under controlled conditions, capturing both response signals and drift patterns.
- Model Architecture Design: Implement a Temporal Convolutional Neural Network (TCNN) with the following specifications:
- Causal convolutions to ensure real-time operation
- Hadamard transform layer for spectral feature extraction
- Residual gated connections for adaptive feature weighting
- Model Training: Train the TCNN model to predict drift-compensated sensor values from raw input sequences.
- Model Quantization: Apply post-training quantization to reduce model size by over 70% while maintaining accuracy below 1 mV mean absolute error.
- Deployment: Compile the quantized model using TensorFlow Lite Micro and deploy to the microcontroller.
- Validation: Continuously monitor model performance in real-time operation, comparing against periodic reference measurements.
Application in Biomedical Monitoring Systems
The challenge of sensor drift is particularly acute in specific biomedical monitoring applications where accuracy and reliability are paramount.
Intravascular Biosensors: These devices face unique challenges due to direct exposure to blood components, which can lead to rapid biofouling and chemical drift [4]. For continuous glucose monitoring systems deployed in intravascular configurations, drift compensation is essential for accurate glycemic control. Studies have demonstrated systems like the GluCath System, which uses fluorescence quenching for optical blood glucose measurement, can maintain acceptable accuracy during 48-hour placement in the radial artery of post-surgical patients when proper drift compensation is employed [4].
Bioprocess Monitoring: In pharmaceutical manufacturing, sensor arrays embedded in bioreactors require uninterrupted operation throughout lengthy batch processes. The MPC approach is particularly valuable here, as it can utilize periodic offline samples as pseudo-calibration points without interrupting the bioprocess [3]. This enables continuous monitoring of critical biomarkers, metabolites, and process variables essential for optimizing biopharmaceutical production.
Implantable Diagnostic Devices: Long-term implantable sensors for continuous monitoring of physiological parameters (e.g., oxygen, pH, electrolytes) face progressive aging-related drift compounded by the body's foreign body response [4]. Advanced drift compensation algorithms that can operate within the strict power constraints of implantable electronics are essential for the viability of these devices.
Sensor drift remains a critical challenge in continuous biomedical monitoring, but emerging approaches like Multi Pseudo-Calibration and AI-based compensation techniques offer promising solutions. The MPC framework specifically addresses the practical constraint of inaccessible sensors by leveraging opportunistic ground-truth measurements, making it particularly valuable for implanted and embedded monitoring applications.
Future research directions should focus on several key areas. First, developing adaptive MPC systems that can automatically optimize the frequency and timing of pseudo-calibration based on drift dynamics. Second, creating hybrid models that combine the explicit ground-truth referencing of MPC with the continuous adjustment capabilities of AI-based methods like TCNNs and domain-adaptive networks. Finally, standardization of drift characterization protocols across the biomedical sensor community would enable more meaningful comparisons between compensation techniques and accelerate progress in this critical field.
As biomedical monitoring systems continue to evolve toward greater miniaturization, longer deployment durations, and higher-stakes clinical applications, robust drift compensation methodologies will remain an essential component of reliable healthcare monitoring and pharmaceutical development.
Continuous monitoring using sensor arrays is critical in various fields, including healthcare and industrial bioprocessing. A significant challenge in these applications is the degradation of sensor accuracy over time due to drift and aging effects. Traditional recalibration methods, which rely on periodic exposure to stable reference analytes, become impractical in deeply-embedded systems such as sensors integrated within a bioreactor. Physical interruption for recalibration is often not feasible, necessitating alternative strategies that operate without process interruption [3]. This document frames these limitations and solutions within the broader research on the Multi Pseudo-Calibration (MPC) approach, detailing specific protocols and experimental validations for the scientific community.
The Multi Pseudo-Calibration (MPC) Approach
The MPC approach is designed to compensate for sensor drift without requiring physical recalibration or process interruption. It operates on the principle of using historical sample measurements with known ground-truth concentrations as "pseudo-calibration" points. The core mechanism involves constructing an input vector that incorporates the difference between current sensor readings and those from a pseudo-calibration sample, the ground-truth concentration of that sample, and the time elapsed between measurements [3].
Key Advantages:
- Non-Linear Drift Modeling: Learns complex, time-dependent drift patterns.
- Data Augmentation: Quadratically increases the training set size by pairing all available samples, enhancing model robustness. Given N training samples, the augmented set contains N(N-1)/2 samples.
- Variance Reduction: When multiple pseudo-calibration points are available, predictions relative to each are generated and averaged, reducing prediction variance [3].
Implementation Framework: The MPC method can be implemented on top of various regression models. Studies have successfully deployed it using:
- Partial Least Squares (PLS)
- Extreme Gradient Boosting (XGB)
- Multi-Layer Perceptrons (MLP) [3]
The following workflow diagram illustrates the MPC process from data acquisition to final prediction.
Comparative Analysis of Drift Compensation Techniques
Multiple drift-compensation strategies exist, each with distinct advantages and limitations, particularly for deeply-embedded systems. The following table summarizes the key techniques identified in the literature.
Table 1: Drift Compensation Techniques for Sensor Arrays
| Technique | Core Principle | Key Advantage | Key Limitation for Deeply-Embedded Systems |
|---|---|---|---|
| Periodic Recalibration [3] | Periodic exposure to a stable reference analyte. | High accuracy if reference is reliable. | Not feasible without interrupting the ongoing process. |
| Multi Pseudo-Calibration (MPC) [3] | Uses historical ground-truth samples as internal calibration points. | No process interruption; utilizes available offline data. | Requires occasional offline analysis for ground truth. |
| Drift Correction Autoencoder (DCAE) [3] | Uses a transfer learning approach with autoencoders to correct for instrumental variation and drift. | Does not require explicit reference measurements during deployment. | Performance may depend on the initial calibration data and drift characteristics. |
| Simultaneous Calibration & Detection [6] | Uses a linear regression algorithm on data from analyte-added samples to offset environmental interference. | Compensates for pH, temperature, and co-pollutants; reduces batch fabrication deviations. | Primarily demonstrated for specific electrochemical sensors (e.g., DPV). |
| Model-Free Predictive Control (MFPC) [7] | Replaces the physical system model with an ultra-local model estimated online. | Robust to system parameter variations and unmodeled dynamics. | Primarily applied in power electronics control; estimation of unknown parts can be complex. |
Experimental Validation and Performance Metrics
Evaluation of MPC on Chemical Sensor Arrays
- Objective: To validate the performance of the MPC approach against baseline methods in the presence of sensor drift.
- Sensor Platform: An array of hydrogel-based magneto-resistive sensors was used for bioprocess monitoring [3].
- Evaluation Procedure:
- Validation Method: Leave-one-probe-out cross-validation.
- Data Splitting: For each of the 4 sensor probes, data was split: the first 75% of measurements from 3 probes for training, and the last 25% of measurements from the held-out probe for testing. This effectively tests drift performance on unseen data from a temporally later period [3].
- Compared Models:
- Baseline 1: Standard regression models (PLS, XGB, MLP) without drift compensation.
- Baseline 2: Drift Correction Autoencoder (DCAE), a state-of-the-art method.
- Proposed Method: MPC implemented on top of PLS, XGB, and MLP.
- Performance Metrics: The primary metric was the Root Mean Square Error (RMSE) of predicted analyte concentrations against ground truth, with lower values indicating better performance and drift compensation [3].
- Key Findings: The MPC approach demonstrated superior drift compensation compared to both baselines across all tested regression techniques, showing a significant reduction in prediction error on the temporally later test data [3].
Performance in Simulated Environments
A thorough characterization was performed on a synthetic dataset that simulated varying degrees of sensor cross-sensitivity and sensor drift. The results confirmed the robustness of the MPC method under controlled conditions where the drift parameters were known, reinforcing its applicability for long-term deployments [3].
Detailed Experimental Protocols
Protocol 1: Validating MPC for Bioprocess Monitoring
This protocol outlines the steps to replicate the experimental validation of the MPC approach as described in the search results [3].
- 1. Sensor Array Setup & Data Acquisition:
- Deploy a cross-sensitive chemical sensor array (e.g., hydrogel-based magneto-resistive) into the bioreactor or monitoring environment.
- Continuously log sensor measurements from all array elements at a defined sampling frequency.
- Periodically (e.g., once per day or at key process stages), extract a physical sample from the system.
- Analyze the extracted sample using a high-precision offline analyzer (e.g., HPLC, mass spectrometry) to obtain the ground-truth concentration of the target analytes. Record the timestamp of this sample.
- 2. Data Preparation & Pseudo-Calibration Point Creation:
- Synchronize the sensor data with the offline analysis results using timestamps.
- For each offline sample, create a pseudo-calibration data point, which is a tuple containing:
[sensor_measurements, ground_truth_concentrations, timestamp]. - Store all pseudo-calibration points in a chronological database.
- 3. Model Training with MPC Augmentation:
- For a given current sensor measurement
S_currentat timet_current, construct an augmented dataset. - For each stored pseudo-calibration point
i(with dataS_i,C_i,t_i), create a new input vector:[S_current - S_i, C_i, t_current - t_i]. The target output is the ground-truth concentrationC_i. - Use this augmented dataset to train the chosen regression model (PLS, XGB, or MLP). The model learns to predict concentration based on the differential signal and time lag.
- For a given current sensor measurement
- 4. Model Testing & Validation:
- To evaluate performance, use a leave-one-probe-out or a similar temporal cross-validation scheme.
- Use the first portion of the dataset (e.g., 75%) for training and the latter portion (e.g., 25%) for testing to simulate and evaluate drift compensation.
- Generate predictions for the test set and calculate performance metrics like RMSE.
Protocol 2: Anti-Interference Validation for Electrochemical Sensors
This protocol is adapted from recent research on simultaneous calibration and detection, which shares the core principle of using internal data for calibration against interference [6].
- 1. Sensor Preparation & Solution Setup:
- Utilize electrochemical sensors, such as those designed for differential pulse voltammetry (DPV).
- Prepare a series of standard solutions with known, varying concentrations of the target analytes (e.g., 40-100 μM nitrite and 100-400 μM sulfite).
- Prepare interfering substance solutions and buffer solutions to adjust pH.
- 2. Data Collection under Interference:
- For each standard solution, perform DPV measurements under:
- Normal conditions.
- pH fluctuations (e.g., ±1 pH unit).
- Temperature changes (e.g., ±5°C).
- With high concentrations of interfering substances added to the solution.
- Record the full DPV response for each condition.
- For each standard solution, perform DPV measurements under:
- 3. Calibration Model Development:
- Develop a multi-analyte linear regression algorithm (or similar).
- The model should use features from the DPV scans (e.g., peak currents, potentials) to predict concentration, inherently compensating for the variations introduced by the controlled interferences.
- 4. Performance Assessment:
- Calculate the relative error for repeat measurements and across different sensor batches.
- Validate the model on actual water samples and compare its accuracy against standard laboratory methods.
The logical flow of the experimental validation process, from hypothesis to conclusion, is summarized in the following diagram.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 2: Key Reagents and Materials for Sensor Array Drift Compensation Studies
| Item | Function & Application | Specific Example |
|---|---|---|
| Cross-Sensitive Sensor Array | The core sensing element; provides a multi-dimensional signal response to target analytes and interferents. | Hydrogel-based magneto-resistive sensor array [3]. |
| Offline Analytical Reference | Provides ground-truth data for pseudo-calibration points; essential for model training and validation. | High-performance liquid chromatography (HPLC), mass spectrometer, or other certified analytical instruments [3]. |
| Standard Analytic Solutions | Used for preparing known concentrations of target analytes for initial calibration and creating simulated drift scenarios. | Certified reference materials (CRMs) for nitrite (NO₂⁻), sulfite (SO₃²⁻), or other relevant analytes [6]. |
| Interferent Substances | Used in validation experiments to test the robustness and anti-interference performance of the calibration model. | Common co-pollutants or specific salts in water analysis [6]. |
| Buffer Solutions | Used to control and vary pH levels during experimental validation to test model performance under environmental fluctuations. | Phosphate or carbonate buffers at different pH levels [6]. |
| Regression Modeling Software | Platform for implementing the MPC data augmentation and training the machine learning models. | Python with scikit-learn (for PLS, MLP), XGBoost library (for XGB) [3]. |
Core Concept and Principle
The Multi Pseudo-Calibration (MPC) approach is an advanced on-site calibration technique designed to compensate for time-dependent drift in arrays of cross-sensitive chemical sensors during continuous, long-term monitoring. The methodology is particularly vital for applications where traditional periodic recalibration using external references is impossible, such as in deeply-embedded sensors within bioreactors or other uninterrupted industrial processes [3].
The foundational principle of MPC is the use of historical sensor measurements for which ground-truth analyte concentrations are later obtained via offline analysis. These data points are treated as "pseudo-calibration" samples. The MPC framework incorporates these samples into a regression model, enabling the system to learn a non-linear model of the sensor drift without interrupting the ongoing process [3].
Table 1: Core Problem and MPC Solution Overview
| Aspect | Challenge in Continuous Monitoring | MPC Solution |
|---|---|---|
| Drift & Aging | Degrades sensor accuracy over time, leading to inaccurate quantification of analytes [3]. | Uses pseudo-calibration points to model and correct for time-dependent drift. |
| Recalibration | Often infeasible without interrupting the process (e.g., in embedded bioreactor sensors) [3]. | Leverages offline analyte concentration measurements from periodically extracted samples. |
| Data Scarcity | Limited labeled data for training robust models in long-term deployments. | Quadratically increases training data by pairing all historical samples with each other. |
The following diagram illustrates the core logical workflow and relationships of the MPC approach.
Implementation and Workflow
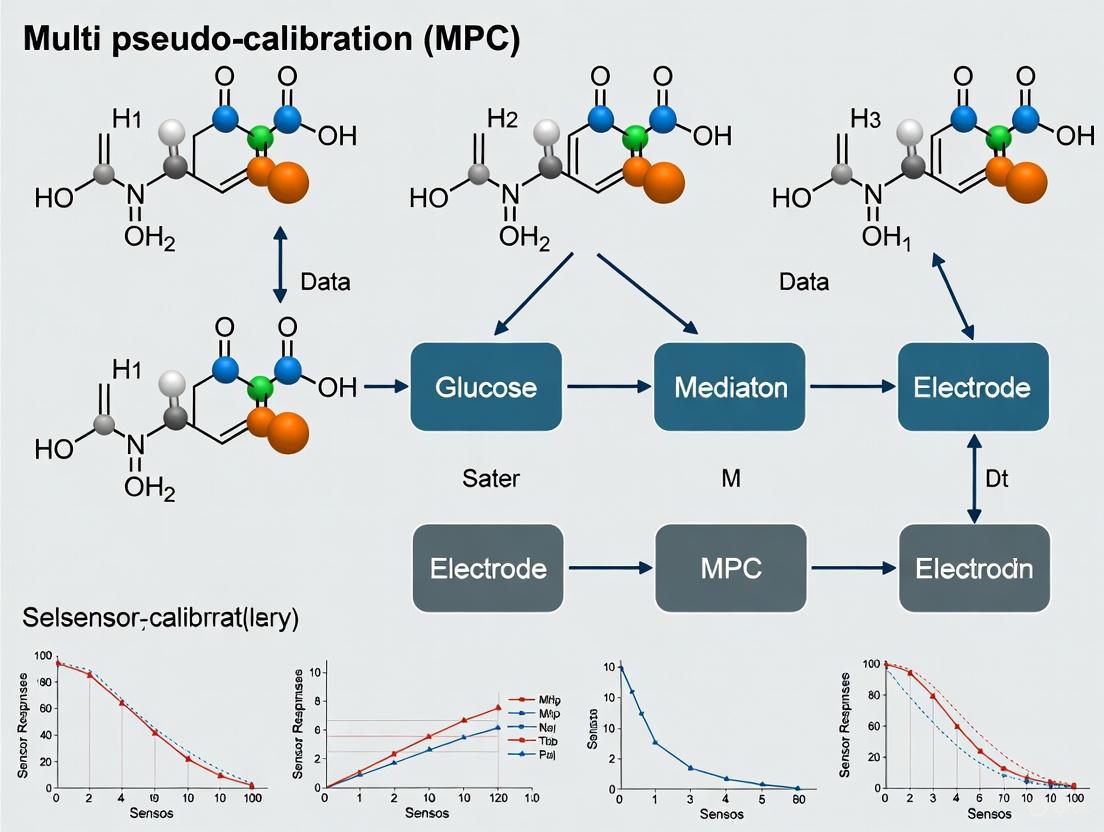
The MPC technique is implemented by constructing a specialized input vector for the regression model. This input concatenates three key pieces of information: the difference between current sensor readings and those from a past pseudo-calibration sample, the ground-truth concentration for that pseudo-sample, and the time elapsed between the two measurements [3]. This approach allows the model to dynamically correct predictions based on known anchor points.
Table 2: Components of the MPC Input Vector
| Input Component | Symbol | Description | Role in Drift Compensation |
|---|---|---|---|
| Sensor Measurement Delta | Δs = s(t~current~) - s(t~pseudo~) | Difference between current sensor readings and sensor readings at the pseudo-calibration time. | Provides the raw signal change that the model must correct. |
| Ground Truth Concentration | C~pseudo~ | Analytically measured reference concentration of the pseudo-calibration sample. | Serves as an absolute reference point for recalibration. |
| Time Difference | Δt = t~current~ - t~pseudo~ | Time elapsed since the pseudo-calibration sample was taken. | Enables the model to learn and account for time-dependent drift dynamics. |
This framework integrates with standard regression techniques. Research has demonstrated successful implementation using Partial Least Squares (PLS), eXtreme Gradient Boosting (XGB), and Multi-Layer Perceptrons (MLP) [3].
The MPC approach offers three distinct algorithmic advantages [3]:
- Non-Linear Drift Modeling: It can learn complex, non-linear relationships between sensor drift, time, and analyte concentration.
- Quadratic Data Augmentation: For a training set with N samples, MPC can generate N(N-1)/2 training pairs by using each sample with every previous sample, drastically increasing the effective training data.
- Variance Reduction: When multiple pseudo-calibration samples are available, MPC can generate predictions relative to each and average the results, reducing prediction variance.
The complete operational workflow for implementing MPC is outlined below.
Experimental Validation and Performance
The performance of the MPC approach was rigorously evaluated against established baselines, including standard regression models and a state-of-the-art Drift Correction Autoencoder (DCAE) [3]. The validation utilized an experimental dataset from an array of hydrogel-based magneto-resistive sensors used for bioprocess monitoring, as well as synthetic datasets to characterize performance under controlled conditions [3].
The evaluation employed a leave-one-probe-out cross-validation technique. The dataset was split, using the first 75% of measurements from training probes for model development and the last 25% from all probes for testing. This methodology specifically targets the evaluation of model performance under drift conditions [3].
Table 3: Key Regression Models Used with MPC
| Model | Type | Key Characteristics | Suitability for MPC |
|---|---|---|---|
| Partial Least Squares (PLS) | Linear Projection | Models relationships between observed variables via latent structures. Reduces dimensionality. | Effective for linear relationships and multi-collinear sensor data. A strong, interpretable baseline. |
| eXtreme Gradient Boosting (XGB) | Ensemble Tree | Builds sequential decision trees, correcting errors from previous ones. Handles non-linearities well. | High performance for complex, non-linear drift dynamics. Often provides high accuracy. |
| Multi-Layer Perceptron (MLP) | Neural Network | A class of feedforward artificial neural network with multiple layers. Universal function approximator. | Excellent for learning highly complex and non-linear drift patterns. Requires more data and tuning. |
Detailed Experimental Protocol
This section provides a step-by-step protocol for implementing and validating the MPC approach, based on the methodology outlined in the research [3].
Sensor Array Setup and Data Acquisition
- Sensor Preparation: Deploy an array of cross-sensitive chemical sensors (e.g., hydrogel-based magneto-resistive sensors) into the target environment (e.g., a bioreactor).
- Data Collection:
- Record sensor measurements from all array elements at a defined sampling frequency (e.g., every minute).
- For the training set, apply open-loop actuations or expose the system to normal operational variations to generate a rich dataset. This is analogous to generating random control signals to excite the system's dynamics, as performed in other sensor system modeling work [8].
- Time-stamp all sensor readings.
Generation of Pseudo-Calibration Points
- Sample Extraction: At periodic, pre-defined intervals (e.g., every 4-8 hours), extract a physical sample from the monitoring environment without interrupting the process.
- Offline Analysis: Analyze the extracted sample using a high-precision offline analytical method (e.g., HPLC, GC-MS, or reference analyte analyzer) to obtain the ground-truth concentration of the target analyte(s).
- Data Logging: Log the obtained ground-truth concentration with the corresponding sensor measurements and the exact timestamp of sample extraction. This forms one pseudo-calibration point.
Model Training with MPC
- Data Preparation for MPC:
- Compile a dataset of N samples, each containing sensor readings and any available ground-truth concentrations.
- For MPC training, create an augmented dataset by pairing each sample i with every previous sample j (where j < i) for which ground truth is available.
- For each pair (i, j), construct the MPC input vector:
[s_i - s_j, C_j, t_i - t_j], wheresis the sensor measurement vector,Cis the ground truth concentration, andtis the timestamp. - The target output for this input vector is the ground truth concentration of sample i, C_i.
- Model Training:
- Choose a regression algorithm (PLS, XGB, MLP).
- Split the augmented dataset into training and validation sets, ensuring temporal consistency (e.g., using the first 75% of data chronologically for training).
- Train the model to predict the target concentration from the MPC input vector.
System Evaluation and Validation
- Test Set Configuration: Use a leave-one-probe-out or similar temporal cross-validation strategy. Reserve the last 25% of data from the test probe(s) for final evaluation to assess performance on drifted data [3].
- Performance Metrics: Evaluate model performance using standard metrics:
- Root Mean Square Error (RMSE)
- Mean Absolute Error (MAE)
- Integral of Time-weighted Absolute Error (ITAE) - useful for emphasizing persistent errors over time [9].
- Coefficient of Determination (R²)
- Comparison to Baselines: Compare the MPC-enabled model against two baselines:
- A standard regression model using only current sensor measurements.
- A state-of-the-art drift-correction method, such as a Drift Correction Autoencoder (DCAE).
The Scientist's Toolkit
Table 4: Essential Research Reagents and Materials for MPC Implementation
| Item | Function/Description | Example/Notes |
|---|---|---|
| Cross-Sensitive Sensor Array | The core sensing element; provides multivariate response to analytes and interferents. | Hydrogel-based magneto-resistive sensors; metal-oxide semiconductor arrays; electrochemical sensor arrays. |
| Offline Reference Analyzer | Provides ground-truth analyte concentration for pseudo-calibration samples. | HPLC, GC-MS, UV-Vis Spectrophotometer, or other validated analytical instrumentation. |
| Data Acquisition System | Logs time-synchronized sensor measurements from the array. | National Instruments DAQ, or other systems capable of multi-channel, timestamped data logging. |
| Regression Modeling Software | Platform for implementing and training MPC-enabled regression models. | Python (Scikit-learn, XGBoost, PyTorch/TensorFlow), MATLAB, R. |
| Bioreactor or Process Vessel | The application environment for continuous, uninterrupted monitoring. | Bench-top or pilot-scale bioreactor with ports for sensor insertion and sample extraction. |
This application note details the theoretical foundation and experimental protocols for learning non-linear drift models from historical data, contextualized within the multi pseudo-calibration (MPC) framework for sensor arrays. Concept drift, the phenomenon where input data distributions change over time, significantly degrades the predictive performance of models in long-term sensor deployments [10]. Recurring drifts are particularly common in sensor systems due to cyclical environmental factors or operational regimes. This work posits that by identifying and modeling these non-linear drifts from historical data, MPC systems can autonomously trigger calibration routines or adjust sensor readings, thereby maintaining data integrity and reducing reliance on physical calibration standards. We present DriftGAN, an unsupervised method based on Generative Adversarial Networks (GANs) that detects concept drifts and identifies whether a specific drift configuration has occurred previously [10]. This approach minimizes the data and time required for the system to adapt to recurring drift patterns, enhancing the resilience and autonomy of sensor array networks.
Theoretical Foundation
The Problem of Concept Drift in Sensor Arrays
In real-world sensor applications, input data distributions are rarely static over extended periods [10]. This concept drift adversely affects model performance, necessitating robust detection and adaptation mechanisms. For sensor arrays, drifts can originate from various sources:
- Sensor degradation: Physical wear altering sensor response characteristics.
- Environmental changes: Cyclical variations in temperature, humidity, or pressure.
- Operational regime changes: Shifts in measurement contexts or target phenomena.
Unlike traditional drift detection methods that merely identify distribution changes, our approach specifically addresses recurring drifts—patterns that reappear periodically or under specific conditions [10]. In MPC, recognizing these recurrences enables proactive calibration by matching current drift patterns to historical instances where calibration parameters were successfully established.
DriftGAN Architecture for Unsupervised Recurring Drift Detection
The DriftGAN framework implements a multiclass-discriminator GAN architecture containing a discriminator module that simultaneously distinguishes between real and artificial examples while classifying current input data into previously encountered drift categories [10]. Key architectural components include:
- Growing Discriminator Network: As new drift distributions are identified, the discriminator incrementally expands by adding output classes, enabling recognition of an increasing repertoire of drift patterns.
- Historical Distribution Memory: The system maintains a repository of previously encountered data distributions, allowing rapid augmentation of retraining datasets when recurring drifts are detected.
- Unsupervised Operation: Unlike supervised methods that require immediate label availability, DriftGAN operates solely on input distribution changes, making it suitable for sensor environments where ground truth is sporadically available [10].
Integration with Multi Pseudo-Calibration (MPC)
The MPC framework leverages multiple reference sources or statistical signatures for self-calibration. Integrating non-linear drift modeling enhances MPC by:
- Drift-Aware Sensor Fusion: Adjusting fusion weights based on recognized drift patterns.
- Calibration Triggering: Automatically initiating calibration cycles when novel or recurring drifts exceed thresholds.
- Historical Parameter Recall: Retrieving previously successful calibration parameters for recurring drift scenarios, reducing calibration time and resources.
For complex sensor arrays with direction-dependent gains, multi-source self-calibration approaches using weighted alternating least squares (WALS) can be extended with drift detection to handle time-varying calibration parameters [11].
Experimental Protocols
Protocol 1: Data Preparation and Feature Engineering
Objective: Prepare sensor historical data for non-linear drift modeling.
Materials and Reagents:
- Historical sensor readings with timestamps
- Environmental contextual data (temperature, humidity, etc.)
- Computational resources for time-series processing
Procedure:
- Data Collection: Gather continuous sensor readings spanning multiple operational cycles and environmental conditions. Include periods with known calibration events for validation.
- Temporal Segmentation: Divide data into fixed-interval windows (e.g., 1-hour segments) with 50% overlap to capture temporal patterns.
- Feature Extraction: For each window, calculate:
- Statistical moments (mean, variance, skewness, kurtosis)
- Spectral features (dominant frequencies, spectral entropy)
- Cross-sensor correlation coefficients
- Distribution similarity measures relative to baseline
- Feature Normalization: Apply z-score normalization to all features to ensure uniform scaling.
- Dataset Construction: Create labeled examples where each data point represents a temporal window with features, labeled with drift category if known.
Quality Control:
- Validate temporal alignment across sensor channels
- Remove outliers resulting from sensor malfunctions or communication errors
- Ensure balanced representation across operational conditions
Protocol 2: DriftGAN Model Training
Objective: Train DriftGAN model to identify and categorize recurring drift patterns.
Materials and Reagents:
- Prepared feature dataset from Protocol 1
- Deep learning framework (TensorFlow/PyTorch) with GAN implementations
- GPU-accelerated computing resources
Procedure:
- Network Initialization:
- Generator: 3 fully connected hidden layers (256, 512, 256 units) with ReLU activation
- Discriminator: 3 convolutional layers with increasing filters (64, 128, 256) followed by multiclass classification head
- Training Configuration:
- Batch size: 64
- Learning rate: 0.0002 (Generator), 0.0001 (Discriminator)
- Loss function: Wasserstein loss with gradient penalty
- Optimizer: Adam (β₁=0.5, β₂=0.999)
- Training Loop:
- For each epoch:
- Sample minibatch of real sensor features {x} from historical data
- Sample minibatch of random noise {z}
- Generate fake samples {G(z)}
- Update Discriminator to classify real vs. fake and assign drift categories
- Update Generator to fool Discriminator's real/fake discrimination
- Monitor training stability using gradient norms and loss trajectories
- For each epoch:
- Model Selection: Save model checkpoints based on discriminator accuracy and generator diversity metrics.
Quality Control:
- Monitor for mode collapse in generator
- Validate discriminator performance on held-out validation set
- Ensure balanced training across drift categories
Protocol 3: MPC Integration and Validation
Objective: Integrate trained drift model with MPC system and validate performance.
Materials and Reagents:
- Trained DriftGAN model from Protocol 2
- Sensor array system with programmatic calibration interface
- Validation dataset with known ground truth
Procedure:
- Real-time Monitoring:
- Extract features from incoming sensor data using sliding windows
- Pass features through trained DriftGAN discriminator for drift classification
- Compute confidence scores for drift category assignments
- Calibration Triggering:
- When novel drift detected with high confidence, trigger full calibration cycle
- When recurring drift identified, retrieve historical calibration parameters
- Implement graduated response based on drift magnitude and confidence
- Performance Validation:
- Compare sensor accuracy with and without drift-adaptive MPC
- Measure time to correct calibration after drift onset
- Quantize reduction in physical calibration events
- Model Updates:
- Periodically retrain DriftGAN with newly acquired data
- Implement continuous learning protocol to incorporate new drift patterns
Quality Control:
- Establish performance baselines against standard calibration protocols
- Validate calibration decisions against ground truth measurements
- Monitor for false positive drift detections that trigger unnecessary calibrations
Data Presentation
Performance Comparison of Drift Detection Methods
Table 1: Comparison of unsupervised drift detection methods on sensor array datasets. Performance measured by F1 score for drift detection accuracy.
| Method | Principle | Average F1 Score | Recurring Drift Identification | Computation Load |
|---|---|---|---|---|
| DriftGAN (Proposed) | GAN-based multiclass discrimination | 0.89 | Yes | Medium-High |
| OCDD | One-Class SVM with sliding windows | 0.82 | No | Medium |
| Discriminative Drift Detector | Linear regressor on two windows | 0.76 | No | Low |
| Incremental K-S Test | Statistical test with treap data structure | 0.71 | No | Medium |
| ADWIN | Adaptive windowing with statistical tests | 0.79 | No | Low-Medium |
Sensor Data Recovery Metrics with MPC Integration
Table 2: Performance metrics for sensor array data quality with and without DriftGAN-enhanced MPC across different drift scenarios.
| Drift Scenario | Standard MPC | MPC + DriftGAN | Improvement | |||
|---|---|---|---|---|---|---|
| MAE | Time to Recovery (hr) | MAE | Time to Recovery (hr) | MAE Reduction | Time Savings | |
| Slow Linear Drift | 0.32 | 12.4 | 0.15 | 8.2 | 53.1% | 33.9% |
| Abrupt Distribution Shift | 1.24 | 24.7 | 0.58 | 14.3 | 53.2% | 42.1% |
| Recurring Seasonal Pattern | 0.87 | 18.5 | 0.31 | 5.1 | 64.4% | 72.4% |
| Complex Non-linear Drift | 1.52 | 36.2 | 0.79 | 22.6 | 48.0% | 37.6% |
Visualization of Workflows
DriftGAN Model Architecture and MPC Integration
DriftGAN-MPC Integration Workflow
Multi Pseudo-Calibration with Drift Awareness
Drift-Aware MPC Decision Process
The Scientist's Toolkit
Table 3: Essential research reagents and computational tools for implementing non-linear drift models in sensor MPC.
| Item | Function | Implementation Example |
|---|---|---|
| TensorFlow/PyTorch | Deep learning framework for implementing DriftGAN | Flexible GAN architecture with custom discriminator heads |
| Historical Sensor Database | Repository of sensor readings under various conditions | Time-series database with drift period annotations |
| Weighted Alternating Least Squares (WALS) | Multi-source calibration algorithm | Sensor gain and offset estimation using multiple references [11] |
| Feature Extraction Library | Computational tools for signal characterization | Statistical, spectral, and cross-correlation feature calculators |
| Drift Pattern Memory | Storage and retrieval of historical drift patterns | Database of drift features with associated calibration parameters |
| Ensemble Learning Framework | Combination of multiple models for robust prediction | Integration of LSTM forecasts with drift classification [12] |
| Validation Dataset | Ground truth data for model evaluation | Sensor readings with known calibration states and drift events |
In the fields of chemical sensing, environmental monitoring, and bioprocess control, sensor arrays are indispensable for the continuous, real-time measurement of multiple analytes. However, two persistent challenges compromise the accuracy and reliability of these systems: sensor cross-sensitivity and environmental fluctuations. Cross-sensitivity occurs when a sensor responds not only to its target analyte but also to interfering substances, leading to inaccurate readings [13] [14]. Environmental fluctuations—such as changes in temperature, pH, and humidity—can cause signal drift, further degrading sensor performance over time [3] [6]. Traditional calibration methods, which rely on periodic exposure to reference standards, are often ineffective or impractical for systems that require uninterrupted, long-term monitoring, such as deeply-embedded bioreactors [3].
The Multi Pseudo-Calibration (MPC) approach presents a robust solution to these challenges. MPC is an on-site calibration technique designed for situations where traditional recalibration is not feasible. Its core principle involves using historical sensor measurements for which ground-truth analyte concentrations are known (from offline analysis) as "pseudo-calibration" points. These points are fed into a regression model, enabling the system to learn and compensate for non-linear sensor drift and cross-sensitivities without interrupting the monitoring process [3]. This application note details how the MPC framework specifically addresses cross-sensitivity and environmental fluctuations, providing researchers with structured protocols and data to support its implementation.
Core Mechanisms: How MPC Mitigates Interference and Drift
The MPC Architecture for Handling Cross-Sensitivity
Cross-sensitivity is a common phenomenon in sensor arrays, where a sensor's response is influenced by multiple analytes in a complex mixture [13] [14]. The MPC architecture turns this challenge into an advantage. Instead of treating cross-sensitivity as mere noise, the approach uses the unique, composite "fingerprint" response pattern generated across the entire sensor array to identify and quantify individual analytes [15]. When a pseudo-calibration sample is introduced, the model learns the relationship between this multi-sensor fingerprint and the known ground-truth concentration. Subsequent predictions are made by concatenating the difference between current sensor readings and the stored pseudo-calibration measurements, effectively factoring out the consistent component of cross-sensitive responses [3].
The MPC Architecture for Handling Environmental Fluctuations
Environmental factors like temperature and pH are major sources of signal drift. The MPC approach explicitly incorporates these parameters into its model. The input vector for the MPC's regression model includes not only sensor differentials and ground-truth values but also the time difference between the current measurement and the pseudo-calibration point [3]. This allows the model to capture and correct for time-dependent drift. Furthermore, research on advanced sensor systems demonstrates that calibration functions can be significantly improved by utilizing cross-sensitive parameters that influence the parameter of interest [13]. The MPC framework is inherently compatible with integrating these auxiliary environmental readings (e.g., from a colocated temperature or pH sensor) as additional inputs, allowing the model to learn and compensate for their specific effects on the primary sensor array [14].
Table 1: Summary of Challenges and MPC Countermeasures
| Challenge | Impact on Sensor Data | MPC Countermeasure | Key Mechanism |
|---|---|---|---|
| Cross-Sensitivity | Non-selective sensor response; inaccurate quantification of target analytes in mixtures [13] [14]. | Array Fingerprinting & Multi-Variate Regression | Uses the collective response pattern from a cross-sensitive array as a unique identifier, learned against pseudo-calibration ground truths [3] [15]. |
| Environmental Fluctuations (Drift) | Time-varying signal drift due to temperature, pH, humidity, or sensor aging [3] [6]. | Temporal Modeling & Auxiliary Data Integration | Incorporates time difference and environmental data (T, pH) into the model to learn and correct for non-linear drift [3] [13]. |
| Infeasible Recalibration | Performance degradation in embedded systems (e.g., bioreactors) where reference access is impossible [3]. | On-Site Pseudo-Calibration | Uses historical, off-line analyzed samples as internal reference points, eliminating need for external recalibration [3]. |
Figure 1: MPC Workflow for Handling Interference and Drift. The diagram illustrates how environmental fluctuations and cross-sensitivity introduce error, and how the MPC model uses pseudo-calibration samples to correct the sensor signal.
Experimental Validation and Performance Data
The efficacy of the MPC approach in handling real-world complexities has been validated through both targeted experiments and deployments in operational settings. The following tables summarize quantitative evidence of its performance.
Table 2: Performance of Calibration Strategies Against Cross-Sensitivity and Drift
| Calibration Strategy | Experimental Setup | Key Performance Metrics | Outcome in Handling Cross-Sensitivity/Drift |
|---|---|---|---|
| MPC with PLS/XGB/MLP [3] | Bioprocess monitoring with hydrogel-based magneto-resistive sensor array. | Compared against baseline and Drift Correction Autoencoder (DCAE). | Successfully learned non-linear drift model; significantly reduced prediction variance by averaging over multiple pseudo-calibration points. |
| Multi-Pollutant Simultaneous Calibration and Detection (MSCD) [6] | Simultaneous detection of Nitrite (NO₂⁻) and Sulfite (SO₃²⁻) in water with pH/temperature fluctuations. | Relative error ≤ 8.3%; RSD < 3.9% across sensor batches. | Effectively offset interference from pH, temperature, and co-pollutants; reduced batch-to-batch sensor deviation. |
| Multiple Linear Regression (MLR) for Low-Cost Gas Sensors [14] | Year-long field deployment of multi-pollutant monitors (PM2.5, CO, O₃, NO₂, NO). | Pearson correlation (r) > 0.85; RMSE within 0.5 ppb for gas models. | Corrected for identified cross-sensitivities (e.g., NO₂ sensor response to O₃) using other colocated sensor data as predictors. |
Table 3: Quantitative Results from Anti-Interference Electrochemical Sensing (MSCD Strategy) [6]
| Interference Condition | Target Analytic | Concentration Range | Relative Error | Key Achievement |
|---|---|---|---|---|
| pH Fluctuations | Nitrite (NO₂⁻) | 40-100 μM | ≤ 8.2% | Acceptable anti-interference performance without manual recalibration. |
| Temperature Fluctuations | Sulfite (SO₃²⁻) | 100-400 μM | ≤ -8.3% | High accuracy under changing environmental conditions. |
| High Concentration of Interfering Substances | Nitrite & Sulfite | - | < ±7.8% (in actual water samples) | Significantly more accurate than commonly used electrochemical methods. |
| Different Sensor Fabrication Batches | Nitrite & Sulfite | - | < -11.6% and 3.9% | Offset deviation from fabrication batches, ensuring consistency. |
Detailed Experimental Protocols
Protocol 1: Implementing MPC for a Deeply-Embedded Bioreactor Sensor Array
This protocol is adapted from the foundational work on MPC for chemical sensor arrays in bioprocess monitoring [3].
1. Sensor Array Initialization and Baseline Data Collection:
- Procedure: Integrate the cross-sensitive chemical sensor array (e.g., hydrogel-based magneto-resistive sensors) into the bioreactor system. Begin continuous data acquisition from all sensor elements.
- Key Consideration: Ensure data logging captures raw sensor outputs along with precise timestamps.
2. Pseudo-Calibration Sampling:
- Procedure: Periodically extract a small sample from the bioreactor. Analyze this sample using an offline reference method (e.g., HPLC, mass spectrometry) to obtain ground-truth concentrations for all target analytes.
- Data Integration: Log the sensor array readings from the exact time the sample was extracted. Store this data pair
{sensor_readings(t_sample), ground_truth(t_sample)}as a pseudo-calibration point in a dedicated database.
3. MPC Model Training:
- Procedure: Construct an augmented training set. For each data point, create input vectors that concatenate:
- The difference between current sensor measurements and stored pseudo-calibration sensor measurements.
- The ground-truth concentration of the pseudo-calibration sample.
- The time difference between the current measurement and the pseudo-calibration sample.
- Model Selection: Implement the MPC approach on top of a regression model (e.g., Partial Least Squares - PLS, Extreme Gradient Boosting - XGB, or a Multi-Layer Perceptron - MLP). Train the model to predict the current analyte concentration.
4. Validation and Prediction:
- Procedure: Evaluate the model using a leave-one-probe-out cross-validation technique. For deployment, when a new sensor measurement is taken, the MPC system generates predictions relative to all available pseudo-calibration points and averages the results to produce a final, robust concentration value.
Protocol 2: Simultaneous Calibration for Multi-Pollutant Detection in Water
This protocol is based on the MSCD strategy, which shares the core MPC philosophy of in-situ calibration against multiple variables [6].
1. Sensor and Solution Preparation:
- Procedure: Prepare the electrochemical sensor array (e.g., for nitrite and sulfite). Prepare a series of standard solutions with varying, known concentrations of all target pollutants. Also prepare solutions with varying levels of potential interferents (e.g., different pH, temperature, foreign ions).
2. Data Acquisition under Interference:
- Procedure: Using differential pulse voltammetry (DPV), scan the series of standard and interferent-added solutions. Record the full voltammetric response of the sensor array for each solution.
3. Calibration Model Development:
- Procedure: Develop a linear regression algorithm. The model uses the characteristic peak currents (or potentials) from the DPV scans as inputs. It is trained to map these inputs to the known concentrations, while inherently learning to correct for the patterns caused by the interfering conditions.
4. Field Deployment and Testing:
- Procedure: Deploy the calibrated sensor system for actual water sample testing. The model's predictions are compared against reference methods to validate its anti-interference performance and accuracy in real-world scenarios.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 4: Key Research Reagents and Materials for MPC-Based Studies
| Item Name | Function/Description | Application Context |
|---|---|---|
| Cross-Sensitive Sensor Array (e.g., hydrogel-based magneto-resistive; electrochemical) [3] [6] | A group of sensor elements that exhibit partially overlapping responses to different analytes, generating unique fingerprint patterns. | Core sensing element in bioprocess monitoring, environmental water quality, and gas/vapor detection. |
| Pseudo-Calibration Sample | A sample extracted from the monitoring environment and analyzed by a reference-grade offline analyzer to establish ground-truth [3]. | Provides the critical reference data point for the MPC model to learn drift and interference without process interruption. |
| AlphaSense Electrochemical Gas Sensors (e.g., CO-A4, NO2-A43F) [14] | Low-cost gas sensors that output a voltage proportional to gas concentration, often with known cross-sensitivities. | Used in low-cost air quality monitoring networks for pollutants like CO, NO, and NO₂. |
| Plantower PMS A003 Particulate Matter Sensor [14] | A low-cost optical particle counter that estimates PM2.5 mass concentration. | Deployment in multipollutant environmental monitoring stations. |
| Reference-Grade Analyzer (e.g., HPLC, Mass Spectrometer, Teledyne API gas analyzers) [3] [14] | Instruments providing high-precision, high-accuracy concentration measurements for validation and ground-truthing. | Used for analyzing pseudo-calibration samples and for colocation during initial sensor calibration. |
| Microcontroller & Data Logger (e.g., Arduino, custom-built systems) [13] | Hardware for acquiring, processing, and transmitting raw sensor data in real-time. | Enables continuous data collection and the implementation of real-time calibration models. |
Implementing MPC: From Workflow to Real-World Biomedical Applications
Sensor drift presents a fundamental challenge to the reliability of continuous monitoring systems in pharmaceutical development and bioprocess manufacturing. Traditional calibration methods require periodic interruptions to expose sensor arrays to reference analytes, a process that is often impractical for deeply embedded sensors in bioreactors. The Multi Pseudo-Calibration (MPC) approach overcomes this limitation by leveraging historical measurements with known ground-truth concentrations as "pseudo-calibration" points. This method constructs an input vector that concatenates the difference between current sensor measurements and archived pseudo-calibration sample measurements, the ground-truth concentration for the pseudo-sample, and the time difference between measurements. This framework enables the system to learn non-linear sensor drift dynamics without process interruption, significantly enhancing long-term measurement accuracy for critical quality attributes and process parameters [3].
The MPC workflow offers three distinct advantages over conventional calibration techniques. First, it models complex, non-linear drift patterns that simple baseline correction cannot address. Second, it quadratically increases available training data by pairing each sample with previous pseudo-calibration samples, transforming N samples into N(N-1)/2 training instances. Third, when multiple pseudo-calibration samples are available, MPC generates predictions relative to each reference point and averages the results, substantially reducing prediction variance and enhancing measurement reliability for extended pharmaceutical manufacturing campaigns [3].
Quantitative Performance of MPC Methodology
Classification Accuracy Under Drift Conditions
Table 1: Classification Accuracy Improvement with MPC Drift Compensation
| Compensation Method | Baseline Accuracy (%) | Post-Compensation Accuracy (%) | Accuracy Gain (%) | Experimental Context |
|---|---|---|---|---|
| MPC with MLP [3] | ~80 (estimated) | ~95 (estimated) | ~15 | Chemical sensor array, bioprocess monitoring |
| Intrinsic Feature Method [16] | ~70 | ~90 | ~20 | MOS gas sensors, 36-month dataset |
| SVM Ensemble [5] | Not reported | >90 (drift-corrected) | Significant | MOX sensor arrays, long-term deployment |
Sensor System Specifications and Performance Metrics
Table 2: Sensor Array Configurations for MPC Implementation
| Sensor Type | Array Size | Target Analytes | Sampling Duration | Key Performance Metrics |
|---|---|---|---|---|
| Metal-Oxide Semiconductor (MOS) [16] | 8 sensors | Ethanol, Ethylene | Adsorption: 600s, Recovery: 500s | Correct classification rate: >90% after compensation |
| Hydrogel-based Magneto-resistive [3] | Array configuration | Biochemical markers | Continuous, long-term | Mean absolute error reduction >70% with MPC |
| Catalytic CMOS-SOI-MEMS (GMOS) [5] | Multi-pixel | Ethylene, Combustible gases | Real-time, continuous | MAE <1 mV (<1 ppm equivalent) |
Experimental Protocols for MPC Implementation
Protocol 1: Establishing Pseudo-Calibration Database
Purpose: To create a reference database of pseudo-calibration samples for ongoing drift compensation.
Materials:
- Sensor array system (e.g., MOS, electrochemical, or optical sensors)
- Offline analyzer for ground-truth concentration determination
- Data storage system with timestamp capability
- Standardized sample extraction protocol
Procedure:
- Initial System Characterization: Operate sensor array under standard process conditions for minimum stabilization period (e.g., 7 days preheasing for MOS sensors) [16].
- Sample Collection and Analysis:
- Extract periodic samples from the bioreactor or process stream
- Measure analyte concentrations using reference offline analyzer (e.g., HPLC, GC-MS, or reference spectrophotometer)
- Record corresponding sensor array measurements with precise timestamps
- Data Structuring:
- Store each pseudo-calibration sample as a tuple:
{timestamp, sensor_readings_array, ground_truth_concentration} - Maintain database with samples spanning expected operational conditions
- Store each pseudo-calibration sample as a tuple:
- Validation:
- Verify measurement precision across multiple pseudo-calibration samples
- Establish acceptable variance thresholds for pseudo-calibration inclusion
Protocol 2: MPC Model Training and Implementation
Purpose: To develop and deploy drift-compensated prediction models using the pseudo-calibration database.
Materials:
- Historical sensor data with ground-truth measurements
- Machine learning framework (e.g., Python with scikit-learn, TensorFlow)
- Computational resources for model training
- Validation dataset independent of training data
Procedure:
- Feature Engineering:
- Extract both steady-state and transient features from sensor response curves [16]
- Calculate differential features:
ΔSensors = Current_Readings - PseudoCalib_Readings - Compute temporal feature:
Δt = Current_Time - PseudoCalib_Time
Input Vector Construction:
- For each current measurement, create multiple input vectors by pairing with different pseudo-calibration samples
- Construct input vector:
[ΔSensors, PseudoCalib_Concentration, Δt] - This approach generates N(N-1)/2 training instances from N samples [3]
Model Selection and Training:
Drift-Compensated Prediction:
- For new sensor measurements, generate multiple predictions using different pseudo-calibration references
- Compute final prediction as average of individual predictions to reduce variance [3]
- Implement confidence metrics based on prediction consistency across references
Protocol 3: Validation and Continuous Model Refinement
Purpose: To validate MPC performance and establish protocols for model updating during long-term deployment.
Materials:
- Independent validation dataset with known concentrations
- Statistical analysis software
- Model versioning system
Procedure:
- Performance Validation:
- Assess model accuracy on temporally separated test sets (last 25% of each probe's data) [3]
- Compare MPC performance against baseline models without drift compensation
- Evaluate across different drift severity conditions
Model Monitoring:
- Track prediction variance across different pseudo-calibration references as quality metric
- Monitor residual patterns for evidence of model degradation
- Establish criteria for model retraining
Incremental Learning:
- As new pseudo-calibration samples become available, update training dataset
- Periodically retrain models to capture evolving drift characteristics
- Implement change detection to identify significant drift pattern shifts
Workflow Visualization: MPC Implementation
The Scientist's Toolkit: Essential Research Reagents
Table 3: Key Research Reagents and Materials for MPC Implementation
| Reagent/Material | Function in MPC Workflow | Application Context |
|---|---|---|
| Reference Gas Mixtures [16] | Provide known concentration samples for pseudo-calibration | Gas sensor array validation and calibration |
| Hydrogel-based Sensor Arrays [3] | Continuous monitoring of biochemical analytes | Bioprocess monitoring in pharmaceutical production |
| Metal-Oxide Semiconductor (MOS) Sensors [16] | Detect volatile organic compounds and gases | Environmental monitoring, food quality assessment |
| Offline Analyzer (HPLC, GC-MS) [3] | Establish ground-truth concentration for pseudo-samples | Method validation and reference measurement |
| Magneto-resistive Sensing Elements [3] | Transduce chemical signals to electrical measurements | Embedded bioprocess monitoring systems |
| Catalytic Nanoparticle Layers [5] | Enhance sensor selectivity through catalytic combustion | Multi-gas detection in agricultural monitoring |
Within sensor array research, the multi pseudo-calibration (MPC) approach provides a robust framework for managing the complex, non-stationary environments in which these arrays typically operate. A cornerstone of this methodology is the precise acquisition of high-fidelity ground-truth data, a role fulfilled by offline analyzers. These regulatory-grade instruments provide the reference concentrations against which the responses of lower-cost, higher-frequency sensor arrays are calibrated and validated [17] [18]. The integrity of any MPC model is fundamentally dependent on the quality of this ground truth, as it enables the correction for sensor drift, environmental interferents, and cross-sensitivities [2]. This application note details the protocols for the integrated use of offline analyzers in MPC-based research, ensuring the generation of reliable, laboratory-grade data in field deployments.
Experimental Protocols for Co-Location and Data Acquisition
The following section outlines the core experimental procedures for establishing a co-location setup between a sensor array and an offline analyzer, which is critical for collecting the synchronized data required for MPC model development.
Co-Location Experimental Setup
The objective of this protocol is to generate a high-quality dataset where sensor array responses are temporally aligned with accurate concentration measurements from an offline analyzer. This dataset serves as the foundation for initial calibration and subsequent periodic recalibration within the MPC framework.
Materials and Reagents
- Sensor Array Platform: A multi-sensor device (e.g., employing Metal Oxide (MOX) or Electrochemical (EC) sensors) for measuring target analytes (e.g., CO, NO2, O3) and covariate factors (Temperature, Relative Humidity) [18].
- Offline Analyzer: A regulatory-grade reference analyzer (e.g., Teledyne API, Thermo Scientific 48i-TLE) to provide ground-truth concentrations [18].
- Data Logging System: A centralized system capable of recording time-synchronized data from both the sensor array and the offline analyzer.
- Environmental Shelter: A weatherproof enclosure to co-locate the sensor array and the analyzer inlet, protecting them from direct sunlight and precipitation.
Step-by-Step Procedure
- Site Selection: Identify a deployment location representative of the environmental conditions to be monitored, with secure access to power and, if necessary, a regulated air supply for the offline analyzer.
- Instrument Installation: Co-locate the sensor array and the inlet of the offline analyzer in close proximity (typically within 1-2 meters) to ensure they are sampling the same air mass. Mount the inlets at a standard height (e.g., 2-3 meters above ground) to avoid direct vehicle exhaust and ground-level dust [17].
- Synchronization: Synchronize the internal clocks of the sensor array data logger and the offline analyzer to a common time server (e.g., UTC). This is critical for accurate temporal alignment of the datasets.
- Pre-deployment Calibration: According to manufacturer specifications, perform a full calibration of the offline analyzer using certified standard gases. Document the calibration certificates.
- Data Collection Initiation: Begin continuous data collection from both the sensor array (raw signals, T, RH) and the offline analyzer (gas concentrations). The data should be averaged over a common interval (e.g., 1-hour averages) to mitigate the effects of short-term noise and account for the different response times of the instruments [18].
- Routine Maintenance: Perform regular maintenance checks as per the analyzer's operational manual. This includes, but is not limited to, checking for inlet blockages, replacing particle filters, and verifying zero/span settings weekly or bi-weekly.
- Data Export: After a predetermined deployment period (e.g., 3-6 months), export the time-stamped data from both systems for the subsequent alignment and analysis phase.
Data Preprocessing and Alignment
This protocol ensures the raw data from the co-location experiment is correctly formatted and synchronized for MPC model training.
Procedure
- Data Cleaning: Remove any samples where data from either the sensor array or the offline analyzer is missing or flagged as invalid by the instrument's internal diagnostics [18].
- Temporal Alignment: Merge the sensor array dataset and the offline analyzer dataset using the synchronized timestamps. Account for any known system latency between the instruments.
- Feature Engineering: From the raw sensor array signals, extract relevant features for each sensor. As demonstrated in the GSAD dataset, these can include the steady-state response change (ΔR), and exponential moving averages of the response and recovery curves (e.g.,
ema0.001I_S1,ema0.01D_S1) to capture dynamic response characteristics [2]. - Dataset Partitioning: Split the final aligned dataset into training, validation, and testing sets, ensuring that temporal sequence is preserved if dealing with time-series data to avoid data leakage.
Data Analysis and Modeling for MPC
With a curated dataset from the co-location experiment, the following protocols can be applied to build and validate the MPC models.
Model Training for Calibration and Drift Compensation
The goal is to train a machine learning model that maps the multi-dimensional sensor array responses to the ground-truth concentrations provided by the offline analyzer.
Methods
- Define Calibration Function: Frame the problem as a supervised regression task:
Analyte_Calibrated = Φ(Analyte_Raw, X_covariates), whereX_covariatesincludes raw signals from other sensors in the array, temperature, and relative humidity [18]. - Model Selection: Several machine learning models have proven effective for this task. Recent research highlights the consistent performance of a One-Dimensional Convolutional Neural Network (1DCNN) across multiple datasets, which can automatically learn relevant features from the sensor data streams [18]. Alternatively, Iterative Random Forest algorithms can leverage collective data from multiple sensor channels to identify and correct abnormal sensor responses in real-time [2].
- Model Training: Train the selected model using the training dataset. For neural networks, this involves backpropagation and gradient descent. For tree-based methods, it involves recursive partitioning of the feature space.
Addressing Long-Term Drift with Incremental Learning
Sensor drift is a major challenge that can be mitigated within the MPC framework by using ground-truth from offline analyzers for periodic model updates.
Protocol for Incremental Domain-Adversarial Network (IDAN)
- Concept: The IDAN integrates domain-adversarial learning with an incremental adaptation mechanism to manage temporal variations in sensor data [2].
- Implementation:
- The model contains a feature extractor, a label predictor (for concentration regression), and a domain classifier.
- The feature extractor is trained to produce features that are predictive of the gas concentration (based on the label predictor) but indistinguishable between different time periods or "domains" (based on the domain classifier). This forces the model to learn drift-invariant features.
- As new, periodically collected ground-truth data becomes available from the offline analyzer, the model is updated incrementally, adapting to the new data distribution without forgetting previously learned information [2].
The workflow for establishing the co-location experiment and its role in the MPC framework is summarized in the diagram below.
Diagram 1: Co-location experiment workflow for MPC.
The Scientist's Toolkit: Research Reagent Solutions
The table below catalogues the essential materials and instruments required for the experiments described in this application note.
Table 1: Key Research Reagents and Materials for MPC Experiments
| Item Name | Function/Description | Example Use Case in Protocol |
|---|---|---|
| Regulatory-Grade Analyzer | Provides high-accuracy, certified ground-truth concentrations for target analytes. Serves as the reference for sensor array calibration. | Co-located with sensor arrays to generate labeled training data for initial calibration and model updates [18]. |
| Metal Oxide (MOX) Sensor Array | A group of MOX sensor elements that react to various gases, producing a multi-dimensional response pattern for pattern recognition. | Used as the primary, lower-cost sensing platform in electronic noses for gas detection and identification [19] [18]. |
| Electrochemical (EC) Sensor Array | A set of EC sensors, each targeting specific gases, known for lower power consumption and better selectivity in long-term air quality deployments. | Deployed in multi-sensor nodes (e.g., MONICA device) for monitoring pollutants like CO, NO2, and O3 [17] [18]. |
| Certified Standard Gases | Gases with known, certified concentrations used for the periodic calibration and validation of the offline analyzer's accuracy. | Essential for the pre-deployment calibration step of the regulatory-grade analyzer to ensure ground-truth integrity. |
| Data Logging System | Hardware and software for collecting, time-stamping, and storing data streams from both the sensor array and the offline analyzer. | Critical for the data collection and synchronization steps in the co-location experimental setup. |
| Incremental Domain-Adversarial Network (IDAN) | A deep learning model that combines domain adaptation and incremental learning to compensate for sensor drift over long deployments. | Applied in the drift compensation protocol to update models with new ground-truth data without catastrophic forgetting [2]. |
Quantitative Performance of Calibration Techniques
The effectiveness of different calibration models, trained using data from offline analyzers, can be quantitatively assessed using standard metrics. The following table summarizes the typical performance of various machine learning techniques reported in recent literature for calibrating low-cost CO sensors.
Table 2: Performance Comparison of ML Models for Sensor Calibration [18]
| Calibration Model | Reported Performance | Key Characteristics & Notes |
|---|---|---|
| Multiple Linear Regression (MLR) | Basic performance benchmark. | A simple, interpretable model often used as a baseline; may struggle with non-linear relationships. |
| Random Forest Regression (RFR) | Good performance, used in state-of-the-art methods. | An ensemble method robust to outliers; can capture non-linearities without extensive hyperparameter tuning. |
| Gradient Boosting Regression (GBR) | High accuracy, performs well across datasets. | Another ensemble technique that has shown strong and consistent results in recent studies. |
| One-Dimensional Convolutional Neural Network (1DCNN) | Consistently high accuracy across multiple datasets. | Excels at automatically learning features from raw or lightly processed time-series sensor data. |
| Support Vector Regression (SVR) | Good performance under specific conditions. | Performance can be highly dependent on the choice of kernel and hyperparameters. |
The logical flow of the multi pseudo-calibration (MPC) methodology, from data acquisition to deployed model, is visualized below.
Diagram 2: Multi pseudo-calibration (MPC) core logic.
In multi-sensor systems for scientific research and drug development, the raw data streams from individual sensors are rarely sufficient for robust model training. The construction of the input vector—the structured set of data presented to a machine learning model—is a critical step that directly influences the performance of calibration and predictive tasks. Within the broader research context of a Multi Pseudo-Calibration (MPC) approach for sensor arrays, input vector construction becomes the foundational mechanism for harmonizing data from multiple imperfect, uncalibrated sensors. MPC aims to maintain the relative accuracy between an array of sensors without relying on frequent, precise ground-truth calibrations, making it particularly valuable for long-term deployments in dynamic environments.
This application note details a methodology for constructing input vectors by concatenating sensor differences, ground truth, and time deltas. This approach allows machine learning models to learn not only from the absolute sensor readings but also from the relational dynamics between sensors and their evolution over time, which is essential for implementing effective MPC strategies.
Core Concepts and Definitions
The proposed input vector is composed of several key components, each serving a distinct purpose in the context of MPC.
- Sensor Differences: These are the pairwise discrepancies between readings from different sensors in the array measuring the same underlying physical or chemical property. In an MPC framework, these differences are not merely noise; they represent the systematic biases and drifts between sensors that the model must learn to characterize and correct. Calculating these differences provides a relative calibration signal.
- Ground Truth Data: This refers to the high-fidelity, reference measurements against which the sensor array is benchmarked. In MPC, ground truth is not required continuously but is incorporated during initial training and occasional update phases. Its inclusion in the input vector allows the model to learn the absolute scale and to anchor the pseudo-calibration of the sensor array.
- Time Deltas (Δt): This component represents the time elapsed between consecutive sensor readings. Including time deltas is crucial for modeling temporal dynamics such as sensor drift, transient environmental effects, and the rate of change of the measured analyte, which are all critical for predicting long-term sensor behavior in an MPC system.
Methodologies and Experimental Protocols
Input Vector Construction Protocol
The following protocol describes the procedure for creating input vectors for a multi-sensor array within an MPC research project.
Objective: To create a structured input vector for machine learning models that enables Multi Pseudo-Calibration of a sensor array.
Pre-requisites: A time-synchronized dataset containing raw readings from an array of S sensors, corresponding ground truth measurements (sparse or continuous), and precise timestamps.
Data Synchronization: Ensure all sensor data streams are synchronized to a common timeline. As synchronization errors can significantly degrade fusion algorithm performance [20], employ hardware timestamping or a precise software synchronization protocol. The required precision depends on the dynamics of the measured system.
Feature Extraction (Sliding Window):
- For a given time point
t, define a sliding window encompassing theNmost recent data points for each sensor. - Within this window, calculate a representative value for each sensor (e.g., the mean, median, or a set of spectral features extracted using a library like TSfresh [21]).
- For a given time point
Calculate Vector Components:
- Sensor Differences: Compute the pairwise differences between the representative values of all
Ssensors. For example, with 3 sensors (S1, S2, S3), the differences would be:S1-S2,S1-S3,S2-S3. - Ground Truth: Append the ground truth value corresponding to time
t. If no ground truth is available fort, a placeholder (e.g.,NaN) may be used, and the sample reserved for inference rather than training. - Time Deltas: Calculate the time difference
Δtbetween the current reading attand the previous reading.
- Sensor Differences: Compute the pairwise differences between the representative values of all
Vector Concatenation: Construct the final input vector by concatenating the following components in a predefined order:
[Sensor_1_Value, Sensor_2_Value, ..., Sensor_S_Value][Sensor_Diff_1, Sensor_Diff_2, ..., Sensor_Diff_M](whereMis the number of unique pairwise combinations)[Ground_Truth][Time_Delta]
Table 1: Example Input Vector Structure for a 3-Sensor Array
| Vector Component | Example Values | Dimension | Description |
|---|---|---|---|
| Raw Sensor Values | [0.95, 0.87, 1.02] |
3 | Pre-processed readings from sensors S1, S2, S3. |
| Sensor Differences | [0.08, -0.07, -0.15] |
3 | Pairwise differences: S1-S2, S1-S3, S2-S3. |
| Ground Truth | [1.00] |
1 | Reference measurement value. |
| Time Delta | [0.5] |
1 | Time since last measurement (in seconds). |
| Final Input Vector | [0.95, 0.87, 1.02, 0.08, -0.07, -0.15, 1.00, 0.5] |
8 | Concatenated vector for model input. |
Protocol for Validating MPC with Constructed Input Vectors
Objective: To evaluate the efficacy of the constructed input vectors in maintaining sensor calibration relative to ground truth and within the sensor array itself.
Dataset Splitting: Partition the dataset with constructed input vectors into training, validation, and test sets. Ensure the test set contains data from time periods distinct from the training data to properly evaluate temporal generalization.
Model Training: Train a machine learning model (e.g., a regression model like Random Forest or a neural network) to predict the ground truth value using the constructed input vectors. The model's loss function should minimize the error between the prediction and the ground truth.
MPC Performance Metrics: Evaluate model performance on the test set using the following metrics:
- Mean Absolute Error (MAE) against ground truth.
- Predictive R² against ground truth.
- Inter-sensor Consistency: The standard deviation of the calibrated readings from all sensors in the array for the same underlying condition. A lower value indicates successful pseudo-calibration.
Ablation Study: Conduct an ablation study to isolate the contribution of each input vector component. Train and evaluate models using input vectors that systematically omit one component (e.g., no sensor differences, no time deltas). Compare performance to the full model to quantify each component's importance.
The Scientist's Toolkit
Table 2: Essential Research Reagent Solutions for Sensor Fusion and MPC Experiments
| Item | Function/Application | Example Use Case |
|---|---|---|
| TSfresh Python Library [21] | Automates the extraction of a comprehensive set of features from time series sensor data. | Generating descriptive features from raw accelerometer or gyroscope data windows for activity recognition. |
| SensiML Data Studio [21] | Provides an integrated environment for managing, annotating, and visualizing time-series sensor data. | Streamlining the workflow for labeling sensor data segments and building embedded ML classification models. |
| Scikit-learn [21] | Offers a wide array of simple and efficient tools for predictive data analysis. | Training and validating Random Forest or Support Vector Machine (SVM) models for sensor data classification. |
| Hyperion Hyperspectral Data [22] | Serves as a high-resolution spectral library for cross-calibrating multispectral satellite sensors. | Deriving Spectral Band Adjustment Factors (SBAFs) to correct for differences in satellite sensor responses. |
| Wit Motion Sensor [23] | A commercial sensor unit providing data from accelerometers, gyroscopes, and magnetometers. | Collecting primary datasets for human activity analysis and evaluating data fusion techniques. |
Visualized Workflows
MPC Input Vector Construction
Multi Pseudo-Calibration (MPC) Workflow
Continuous monitoring with chemical sensor arrays is critical in fields such as healthcare, pharmaceutical manufacturing, and environmental sensing. However, a pervasive challenge that degrades long-term accuracy is sensor drift, a time-dependent deviation in sensor response [3]. Traditional calibration methods require periodic exposure to reference analytes, which is often impossible in deeply-embedded applications like bioreactors without interrupting the process [3]. The Multi Pseudo-Calibration (MPC) approach overcomes this limitation by leveraging opportunistic ground-truth measurements obtained from periodically extracted samples analyzed with an offline analyzer [3]. These samples become "pseudo-calibration" points, providing reference data to train regression models that can predict and correct for drift without process interruption. The integration of robust regression models—Partial Least Squares (PLS), Extreme Gradient Boosting (XGB), and Multi-Layer Perceptrons (MLPs)—is fundamental to the success of MPC, enabling it to learn complex, non-linear drift dynamics and maintain sensor accuracy over extended periods [3].
Regression Models in MPC: Capabilities and Comparative Performance
The MPC framework is model-agnostic, but its performance varies significantly depending on the chosen regression algorithm. PLS, XGB, and MLPs each offer distinct advantages in handling the high-dimensional, collinear, and non-linear data typical of drifting sensor arrays.
Table 1: Comparison of Regression Models Integrated with the MPC Approach
| Model | Key Strengths | Handling of Non-Linearity | Data Efficiency | Notable Performance in MPC Context |
|---|---|---|---|---|
| Partial Least Squares (PLS) | Reduces data dimensionality, handles multicollinearity effectively [24]. | Limited; primarily a linear model. | High; performs well even with fewer samples. | Provides a robust linear baseline; can be extended with non-linear variants [3] [24]. |
| Extreme Gradient Boosting (XGB) | High predictive accuracy, handles complex non-linear relationships, resistant to overfitting [25] [26]. | Excellent; sequential tree building corrects prior errors. | Moderate; requires sufficient data for optimal performance. | Demonstrates superior performance in calibration tasks; effective for spatial calibration in air quality networks [3] [25]. |
| Multi-Layer Perceptron (MLP) | Universal function approximator; highly flexible for modeling complex systems [3] [27]. | Excellent; capable of learning highly complex, non-linear mappings. | Low; typically requires large amounts of data to generalize well. | Can achieve high accuracy in drift compensation; models non-linear relationships in colorimetric assays [3] [27]. |
Table 2: Exemplary Quantitative Performance of Regression Models in Sensor Calibration
| Model | Application Context | Key Performance Metrics | Citation |
|---|---|---|---|
| RR-XGBoost | Calibration of micro air quality detectors for six pollutants. | Superior to Random Forest, SVM, and MLP on R², MAE, and RMSE [26]. | [26] |
| XGBoost | Spatial calibration of low-cost PM2.5 sensors. | Achieved RMSE as low as 4.19 μg/m³ [25]. | [25] |
| MLP (ANN) | Colorimetric protein concentration assays. | Provides competitive accuracy for quantitative analysis in color sensing [27]. | [27] |
| Ensemble Methods (GBR) | Estimation of dye concentration. | Prediction errors typically in the range of 10–20% [27]. | [27] |
Detailed Experimental Protocols for MPC Workflow
Protocol 1: Data Preparation and Pseudo-Calibration Set Construction
Objective: To prepare sensor array data and construct the augmented dataset required for training MPC-enabled regression models.
- Raw Data Collection: Continuously record time-series measurements from all sensors in the array. Each data point should include a timestamp and the corresponding raw readings from all sensor channels [3].
- Ground-Truth Sampling: Periodically, extract physical samples from the process (e.g., bioreactor). Analyze these samples using a high-precision offline analyzer (e.g., spectrophotometer, chromatograph) to obtain reference analyte concentrations. Record the timestamp for each ground-truth measurement [3].
- Data Preprocessing:
- Handle Missing Data: Apply imputation techniques such as forward-filling or backward-filling to maintain temporal continuity [25].
- Outlier Removal: Identify and remove erroneous readings. One method is to flag data points where the measured value is greater than three times or less than one-third of the average of its adjacent data points [26].
- Temporal Alignment: Align the sensor measurements with the ground-truth data based on their timestamps. Aggregate high-frequency sensor data (e.g., 5-minute intervals) to match the frequency of the ground-truth data (e.g., hourly averages) [26].
- MPC Dataset Augmentation: This is the core step of the MPC paradigm. For a training set with
Nsamples, generate an augmented training set by pairing each sampleiwith every previous samplej(wherej<i) for which ground truth is available [3].- Input Vector Construction: For each pair (i, j), the input feature vector (X_ij) is a concatenation of:
- The difference between the current sensor readings and the pseudo-calibration sensor readings:
Sensor_i - Sensor_j - The ground-truth concentration of the pseudo-calibration sample:
Concentration_j - The time difference between the current and pseudo-calibration sample:
Time_i - Time_j[3].
- The difference between the current sensor readings and the pseudo-calibration sensor readings:
- Output Target: The target for the model is the ground-truth concentration of the current sample,
Concentration_i. This process quadratically increases the training set size from N to approximatelyN(N-1)/2samples, providing a rich dataset for the model to learn the drift function [3].
- Input Vector Construction: For each pair (i, j), the input feature vector (X_ij) is a concatenation of:
Figure 1: Workflow for MPC Data Preparation and Augmentation.
Protocol 2: Model Implementation and Training for Drift Compensation
Objective: To implement and train the PLS, XGB, and MLP models using the augmented MPC dataset.
- Data Partitioning: Split the augmented dataset using a leave-one-probe-out or k-fold cross-validation technique. To explicitly test for temporal drift, use the first 75% of a probe's data for training and the last 25% for testing [3].
- Model Configuration and Training:
- Partial Least Squares (PLS):
- Use the standard PLS regression algorithm.
- The critical hyperparameter is the number of latent variables (components). Determine this optimally using cross-validation on the training set to avoid overfitting [24].
- Extreme Gradient Boosting (XGB):
- Utilize the
XGBRegressorfrom the XGBoost library. - Key hyperparameters include:
max_depth: Maximum depth of a tree (e.g., 3-6).learning_rate: The boosting learning rate (e.g., 0.1).n_estimators: Number of boosting rounds.subsample: Subsample ratio of the training instance.
- For multi-output regression (predicting multiple analytes), set
multi_strategytoone_output_per_tree(default) ormulti_output_treeif using thehisttree method [28].
- Utilize the
- Multi-Layer Perceptron (MLP):
- Implement using a deep learning framework (e.g., TensorFlow, PyTorch) or
MLPRegressorfrom scikit-learn. - Design a network with multiple hidden layers (e.g., 2-4 layers) and non-linear activation functions (e.g., ReLU, Tanh).
- Use a linear activation function for the output layer.
- Optimize using Adam or stochastic gradient descent and train for a sufficient number of epochs with an early stopping callback to prevent overfitting [3] [27].
- Implement using a deep learning framework (e.g., TensorFlow, PyTorch) or
- Partial Least Squares (PLS):
- Model Evaluation: Evaluate the trained models on the held-out test set using metrics such as Root Mean Square Error (RMSE), Mean Absolute Error (MAE), and the coefficient of determination (R²) [3] [26].
Protocol 3: System Validation and Performance Assessment
Objective: To validate the integrated MPC-regression system and assess its efficacy in compensating for sensor drift.
- Benchmarking: Compare the performance of the MPC-enabled models (PLS-MPC, XGB-MPC, MLP-MPC) against two baselines:
- Ablation Study: Systematically remove components of the MPC input vector (e.g., the time difference or the reference concentration) to quantify the contribution of each element to the overall drift compensation performance.
- Robustness Analysis: Test the model's performance under different conditions simulated in synthetic datasets, such as varying degrees of sensor cross-sensitivity and drift severity [3]. This helps characterize the limits of the approach.
- Continuous Deployment: In a production environment, deploy the trained model. As new ground-truth data becomes available from offline analysis, incorporate it into the system as a new pseudo-calibration point, continuously updating the model's reference frame to adapt to long-term aging effects [3].
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Research Reagent Solutions and Materials for MPC Experiments
| Item Name | Function/Application | Specification Notes |
|---|---|---|
| Hydrogel-based Magneto-resistive Sensor Array | Core sensing element for continuous monitoring in liquid phases such as bioreactors [3]. | Provides cross-sensitive responses to multiple analytes, which is crucial for multivariate calibration. |
| Bicinchoninic Acid (BCA) Assay Kit | A colorimetric method for determining protein concentration, used as a model system for ground-truth analysis [27]. | Enables quantitative offline analysis of samples extracted from a bioreactor. |
| Bradford Assay Reagent | An alternative colorimetric method for protein quantification, used for validation [27]. | Provides a second reference method for ground-truth measurements. |
| Raspberry Pi 4B with TCS3200 Color Sensor | A low-cost, customizable digital color sensor system [27]. | Can be used to develop in-line or at-line pseudo-calibration points by reading RGB/HSL values from colorimetric assays. |
| Air Quality Monitoring Station | High-precision reference instrument for gaseous pollutants and particulate matter (PM) [25] [26]. | Serves as the source of ground-truth data for calibrating low-cost sensor arrays in environmental monitoring. |
| SenEURCity Dataset | A public dataset containing co-located low-cost sensor and reference station data from multiple European cities [25]. | Provides a standardized benchmark for validating MPC and other calibration algorithms for air quality sensors. |
Figure 2: Logical data flow in an MPC-integrated sensor system.
Modern bioprocess monitoring relies on the integration of diverse sensor data to control Critical Process Parameters (CPPs) and ensure product quality. Multi pseudo-calibration (MPC) represents an advanced framework that enhances this process by fusing data from multiple sensor types—both hardware and software-based—to create a more robust and accurate estimation of process states. This approach is particularly valuable for monitoring key variables such as metabolite concentrations, biomass, and product titer in real-time, moving beyond the limitations of single-sensor systems [29]. By combining direct in-line sensor measurements with soft sensor estimations through multivariate models, MPC provides a comprehensive monitoring solution that maintains accuracy even when individual sensor readings are missing or unreliable [30] [29].
The foundation of MPC aligns with Process Analytical Technology (PAT) principles, which emphasize real-time monitoring to ensure final product quality [31] [30]. Within bioreactor operations, this integrated approach enables superior process control and optimization, facilitating the transition from descriptive analytics to predictive and prescriptive process management [29].
Application Protocols for MPC-Based Bioprocess Monitoring
Protocol: Implementation of a Moving Horizon Estimator (MHE) for Metabolite Monitoring
This protocol details the implementation of a Moving Horizon Estimator to infer unmeasured metabolite concentrations, such as sugars, in a fed-batch cultivation of Corynebacterium glutamicum, using real-time measurements of biomass and CO₂ [32].
- Experimental Workflow
Step-by-Step Procedure
- Collect Real-time Measurements: Utilize in-situ sensors to obtain continuous measurements of biomass (via optical density or capacitance probes) and CO₂ evolution rate (via off-gas analysis) [32].
- Define Nonlinear Process Model: Develop a kinetic model, such as a Monod model, that mathematically describes the relationship between the measured states (biomass, CO₂) and the unmeasured state (sugar concentration) [32].
- Configure MHE Optimization: Set up the MHE as an on-line optimization problem. Define the horizon length (e.g., data from the most recent 6-12 hours) and implement hard constraints on concentration values to prevent physiologically unfeasible estimates [32].
- Execute Estimation: Run the MHE algorithm at regular intervals (e.g., every 15 minutes). The algorithm will use the model and the sequence of measurements within the time horizon to compute the most likely trajectory of the unmeasured sugar concentration [32].
- Validate with Off-line Samples: Periodically collect sterile samples from the bioreactor for off-line analysis using a reference method like HPLC. This serves to validate the accuracy of the MHE estimates [31] [32].
- Output Sugar Concentration Estimates: The final output is a real-time, validated estimate of sugar concentration, which can be used for process monitoring and control actions, such as adjusting the feed rate [32].
Key Research Reagent Solutions
| Item | Function in Protocol |
|---|---|
| In-situ Biomass Sensor (e.g., Capacitance Probe) | Provides real-time measurements of viable cell density, a critical input variable for the MHE [32] [33]. |
| CO₂ Analyzer | Measures the concentration of CO₂ in the bioreactor off-gas, which is directly linked to metabolic activity [32]. |
| HPLC System | Used for off-line analysis of broth samples to determine actual sugar and metabolite concentrations, serving as validation for the soft sensor [31] [32]. |
Protocol: Establishing a Multivariate Process Monitoring Tunnel
This protocol describes the creation of an intra-stage process monitoring tunnel for a bioreactor unit operation using Multivariate Data Analysis (MVDA). This tunnel provides a visual representation of process health and enables early anomaly detection by comparing current runs to historical data from successful batches [30].
- Experimental Workflow
Step-by-Step Procedure
- Define Process Variables: Identify and list all Critical Process Parameters (CPPs) and Critical Quality Attributes (CQAs) to be included in the model. These may include pH, temperature, dissolved oxygen, nutrient feed rates, and initial cell density [30].
- Collect & Preprocess Historical Data: Gather data for the identified variables from multiple historical batches that achieved desired process outcomes. Clean the data, normalize it, and remove any outliers [30].
- Build PCA Model: Perform Principal Component Analysis (PCA) on the preprocessed historical data. This transforms the many correlated process variables into a smaller set of independent principal components (PCs), such as PC1 and PC2, which capture most of the process variability [30].
- Develop PLS Regression Model: Use Partial Least Squares (PLS) regression to create a predictive model. This model uses the initial data from a running batch to predict its future trajectory and final state [30].
- Construct Monitoring Tunnel: For an intra-stage bioreactor process, create a chart where the x-axis represents process time and the y-axis represents the principal component score. The "tunnel" is defined by the upper and lower bounds (e.g., min/max) and the median of the PC scores from the historical golden batches [30].
- Monitor Active Batch: In real-time, plot the principal component scores of the active batch (and its PLS-predicted future path) onto the tunnel chart. Deviations outside the tunnel boundaries signal a process anomaly [30].
Key Research Reagent Solutions
| Item | Function in Protocol |
|---|---|
| Process Data Warehouse (e.g., OSI PI, TDengine) | A time-series database that manages and integrates high-frequency data from multiple bioreactors and other unit operations, essential for building historical datasets [34] [35]. |
| MVDA Software (e.g., SIMCA, Bio4C ProcessPad, JMP Pro) | Software platform capable of performing PCA, PLS regression, and visualizing the results via scores plots, loadings plots, and process monitoring tunnels [30] [29]. |
| In-line Spectroscopic Probe (e.g., NIR) | Provides real-time data on key process variables like nutrient concentrations, which can be used as inputs for the multivariate models [35] [29]. |
Data Integration and MPC Workflow
The MPC approach requires seamless integration of data from various sources. The following table summarizes the four primary measurement types in bioprocessing and their role in a multi pseudo-calibration framework [31].
| Monitoring Method | Data Role in MPC | Key Characteristics | Suitability for Real-time Control |
|---|---|---|---|
| In-line/In-situ | Primary, real-time data source for parameters like pH, dissolved O₂/CO₂, temperature. | Measurements occur directly inside the bioreactor; real-time data with no delay [31]. | Excellent; the foundation for automated control loops [31]. |
| On-line | Primary, real-time data source for parameters analyzed in an automated bypass loop. | Sample is diverted and automatically analyzed, may be returned to bioreactor; minimal delay [31]. | Excellent; enables real-time control, though setup is more complex [31]. |
| At-line | Secondary data source for validation or parameters not measurable in-situ. | Sample is removed and analyzed near the production process; shorter delay than off-line [31]. | Limited; may be too slow for processes with fast dynamics (e.g., microbial cultures) [31]. |
| Off-line | Reference data for model validation and calibration of soft sensors. | Sample is removed and analyzed in a lab after pretreatment; significant time delay [31]. | Poor; not suitable for control due to delay, but essential for validating accuracy [31] [32]. |
Implementation and Process Integration
The final implementation of an MPC strategy involves closing the loop from data acquisition to process control. A hierarchical automation structure is typically employed, where the MPC functions as a supervisory layer [29].
- Hierarchical Control Structure: The base layer consists of regulatory Proportional-Integral-Derivative (PID) controllers that maintain basic process variables (e.g., temperature, pH) at their setpoints. The MPC supervisory layer resides above this, using the integrated data from the sensor array and soft sensors to calculate optimal future setpoint trajectories for these base-level controllers, aiming to optimize overall process outcomes like final titer or yield [29].
- Data Handling and Modeling: Effective MPC relies on robust data infrastructure. Time-series databases like TDengine can manage high-frequency telemetry data from bioreactors, while virtual tables can be created to streamline access to specific metric groups for dashboarding in tools like Grafana [34]. For model construction, imputation methods are a key tool. These methods use algorithms like Iterative Imputation or Imputation by Regression (IBR) within a PLS model to estimate missing data points, allowing for process prediction and optimization even with incomplete data streams [29].
The transition from single-analyte to simultaneous multi-analyte detection represents a paradigm shift in water quality monitoring, moving from a narrow, targeted analytical approach to a comprehensive environmental surveillance capability. This shift is critical for accurate risk assessment, as pollutants in water bodies rarely exist in isolation and often exhibit complex synergistic or antagonistic interactions. Traditional laboratory-centric methods, while accurate, are ill-suited to capturing the dynamic spatio-temporal variability of contaminant mixtures in real-world aquatic environments [36]. The emergence of sensor array technologies coupled with advanced data processing frameworks now enables the concurrent quantification of multiple chemical species, providing a more holistic picture of water quality. This application note, framed within the broader context of multi pseudo-calibration (MPC) approaches for sensor arrays, details the operational principles, implementation protocols, and performance benchmarks of these advanced monitoring systems, providing researchers with a practical guide for their deployment in diverse aqueous matrices.
Sensor Platforms for Multi-Analyte Detection
The core of simultaneous detection lies in the use of sensor arrays, where multiple sensing elements, each with distinct but potentially overlapping response profiles, generate a composite signal pattern that can be deconvoluted to identify and quantify individual analytes. These platforms are broadly categorized into multi-sensor and virtual sensor arrays.
Table 1: Comparison of Multi-Analyte Sensor Array Platforms
| Platform Type | Transduction Mechanism | Key Analytes | Advantages | Limitations |
|---|---|---|---|---|
| Electronic Tongues (E-Tongues) | Electrochemical (Voltammetry, Potentiometry, Impedance) [37] | Ionic species (e.g., Pb²⁺, Hg²⁺, Cd²⁺), organic compounds [38] | High sensitivity, portability, real-time analysis [38] | Cross-sensitivity to matrix effects, requires robust calibration |
| Acoustic Sensor Arrays (e.g., QCM, SAW) [37] | Mass-sensitive (Frequency shift, dissipation) | Volatile organic compounds (VOCs), biomarkers, pathogens [37] | Label-free, real-time, suitable for gas and liquid sensing [37] | Coating stability, susceptibility to non-specific binding |
| Optical Sensor Arrays | Fluorescence, Colorimetric, SERS, LSPR [38] | Heavy metals, pesticides, organic toxins [38] [36] | Visual or spectroscopic readouts, high sensitivity and selectivity [38] | Potential photobleaching, interference from colored samples |
| Multi-Modal Nano-Sensor Arrays [36] | Fusion of Electrochemical (FET), Vibrational (SERS), and Photoluminescent | Heavy metals, pharmaceuticals, pesticides, microplastics [36] | Wide analyte coverage, very low detection limits, cross-validated data [36] | Complex fabrication, data fusion challenges, higher cost |
The Multi Pseudo-Calibration (MPC) Framework
The MPC approach is a data-centric strategy that enhances the performance and reliability of sensor arrays without requiring exhaustive calibration for every possible analyte and interference. Instead of a one-sensor–one-analyte model, MPC treats the sensor array as a holistic system. It leverages the cross-sensitive responses of multiple sensing elements and employs advanced algorithms to establish a stable calibration model that is robust to environmental variables like pH, temperature, and ionic strength [37] [36]. This is achieved by incorporating reference signals, drift compensation algorithms, and pattern recognition techniques to create a "pseudo-calibration" that remains valid under fluctuating field conditions. This framework is particularly powerful when integrated with the sensor arrays described in Table 1, enabling them to perform reliably in complex, real-world water bodies.
Detailed Experimental Protocols
Protocol A: Deployment of a Multi-Modal Nano-Sensor Array for Trace Pollutants
This protocol describes the procedure for deploying an integrated sensor array combining graphene field-effect transistors (GFET), surface-enhanced Raman spectroscopy (SERS) substrates, and quantum dot (QD) fluorescence for detecting heavy metals, organic micropollutants, and nanoplastics [36].
I. Materials and Reagents
- Sensor Chip: Fabricated 45 mm × 20 mm PDMS microfluidic manifold integrating GFET, Ag/Au-nanostar SERS substrates, and CdSe/ZnS QDs [36].
- Calibration Standards: Stock solutions of target analytes (e.g., Pb²⁺, atrazine, polystyrene nanoplastics) in ultrapure water.
- Carrier Fluid: A background electrolyte solution (e.g., 1 mM KCl) to mimic the ionic strength of the target water body.
- Field Deployment Unit: Unit containing a peristaltic pump, ARM Cortex-M33 microcontroller, NVIDIA Jetson Nano edge-computing module, and power supply [36].
II. Pre-Deployment Laboratory Calibration
- System Priming: Connect the sensor chip to the flow system. Flush with carrier fluid at 0.5 mL/min for 30 minutes to stabilize the baseline signals from all three transducers [36].
- Data Collection for Training Set: Sequentially introduce a series of standard solutions with known concentrations of individual and mixed analytes.
- For GFET: Record current-voltage (I-V) traces to monitor Dirac-point shifts.
- For SERS: Capture full Raman spectra.
- For QD Fluorescence: Record photoluminescence intensity and quenching kinetics.
- Collect a minimum of 28,000 data samples across the concentration range to build a robust training dataset [36].
- Model Training: Train a hybrid Convolutional Neural Network-Long Short-Term Memory (CNN-LSTM) model on the collected dataset. The model should take the raw, synchronized signals as input and output the concentrations of all target analytes.
III. Field Deployment and Monitoring
- Site Setup: Immerse the intake tube of the flow system into the water body (e.g., river). Secure the deployment unit on the bank.
- Continuous Operation: Initiate continuous flow-through analysis. The edge-computing module executes the pre-trained CNN-LSTM model, performing inference on new data in approximately 31 ms [36].
- Data Transmission and Visualization: Transmit quantified concentration data wirelessly to a cloud or local dashboard for real-time visualization and alerting.
Protocol B: Operation of an Acoustic Electronic Tongue (E-Tongue) Using QCM Array
This protocol outlines the use of a Quartz Crystal Microbalance (QCM) array, a type of bulk acoustic wave sensor, for the discrimination of ionic species in water [37].
I. Materials and Reagents
- QCM Array: A flow cell housing multiple (e.g., 4-8) QCM sensors, each coated with a different selective membrane (e.g., polymers, molecularly imprinted polymers (MIPs), ionic liquids) [37].
- Reference Electrode: (If used in conjunction with electrochemical measurements).
- Data Acquisition System: Instrument capable of recording resonance frequency (Δf) and dissipation (ΔD) for each sensor in the array simultaneously.
II. Procedure
- Baseline Acquisition: Pump a baseline solution (e.g., deionized water or a background electrolyte) through the array until stable frequency readings are obtained for all sensors.
- Sample Injection: Introduce the water sample into the flow stream for a fixed period (e.g., 5-10 minutes), allowing analytes to interact with the sensor coatings and cause mass loading.
- Rinsing Phase: Switch back to the baseline solution to rinse off weakly adsorbed species.
- Data Recording: Record the frequency shift (Δf) and, if available, dissipation factor (ΔD) for each sensor throughout the injection and rinsing cycle. The pattern of responses across the sensor array constitutes the sample's unique fingerprint.
- Data Analysis: Employ pattern recognition algorithms (e.g., Principal Component Analysis - PCA, or Artificial Neural Networks - ANNs) to classify the sample or quantify analyte concentrations based on the response fingerprint, leveraging the MPC framework to account for signal drift and matrix effects.
Diagram 1: Workflow for a multi-modal nano-sensor array with edge AI and MPC processing.
Performance Metrics and Data Analysis
Rigorous validation is essential to confirm the reliability of multi-analyte detection systems. The following performance metrics, derived from the cited protocols, provide a benchmark for evaluation.
Table 2: Quantitative Performance of Featured Multi-Analyte Sensor Systems
| Sensor Platform | Target Analytes | Limit of Detection (LoD) | Key Performance Metrics | Application Context |
|---|---|---|---|---|
| Multi-Modal Nano-Sensor [36] | Lead (Pb²⁺) | 12 ppt | R² ≥ 0.93; Mean Absolute Percentage Error < 6% | River water deployment |
| Atrazine | 17 pM | R² ≥ 0.93; Mean Absolute Percentage Error < 6% | River water deployment | |
| Nanoplastics | 87 ng/L | R² ≥ 0.93; Mean Absolute Percentage Error < 6% | River water deployment | |
| Acoustic (QCM) Sensor Array [37] | Volatile Organic Compounds (VOCs) | (Varies with coating) | Pattern recognition for qualitative and quantitative analysis [37] | Gas sensing, E-Nose |
| Biomarkers | (Varies with coating) | Pattern recognition for qualitative and quantitative analysis [37] | Liquid sensing, Biosensing | |
| Electrochemical Sensor Arrays [38] | Heavy Metal Ions (e.g., Pb²⁺, Hg²⁺) | Parts-per-billion (ppb) range [38] | Portability, rapid response, on-site analysis [38] | Industrial effluent monitoring |
Data Processing and the MPC Workflow
The raw data from sensor arrays must be processed to extract meaningful analytical information. The MPC framework is implemented within this workflow to maintain calibration integrity.
- Signal Pre-processing: Raw signals (I-V curves, spectra, frequency shifts) are conditioned. This includes smoothing, baseline correction, and normalization to minimize noise and instrumental artifacts [36].
- Feature Extraction: For each sensor or transducer, key features are extracted. Examples include the Dirac-point voltage from GFETs, intensity of characteristic Raman peaks from SERS, and quenching rate constants from QD fluorescence [36].
- Data Fusion and Pattern Recognition: The feature vectors from all sensors are combined into a unified dataset. Multivariate algorithms (e.g., PCA for visualization, Partial Least Squares Regression - PLSR, or ANN for quantification) are then applied. This step is where the MPC approach shines, as the model learns the complex, multi-dimensional relationship between the sensor array's response pattern and the analyte concentrations, effectively creating a stable calibration model that can handle interferences [37] [36].
- Model Interpretation: Explainable AI (XAI) techniques like SHAP (SHapley Additive exPlanations) can be employed to interpret the deep learning model's predictions, identifying which sensor signals were most influential for a given quantification result, thereby providing mechanistic insight and building user trust [36].
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Reagents and Materials for Multi-Analyte Sensor Arrays
| Item | Function/Description | Example Use Case |
|---|---|---|
| Selective Sensor Coatings | Provide analyte specificity or cross-selectivity to the transducer. | Polymer films, Molecularly Imprinted Polymers (MIPs), aptamers, ionic liquids on QCM or electrochemical electrodes [37]. |
| Functional Nanomaterials | Enhance sensitivity and provide unique transduction mechanisms. | Graphene for FETs, Ag/Au nanostars for SERS, CdSe/ZnS core-shell Quantum Dots for fluorescence [36]. |
| Microfluidic Manifold | Miniaturized fluidic channels for automated, continuous sample delivery to the sensor chip. | PDMS-based flow-cell for a multi-modal nano-sensor array [36]. |
| Calibration Standard Solutions | Solutions of known concentration used to build the initial training model for the sensor array. | Stock solutions of heavy metal ions, pesticides, and emerging contaminants like nanoplastics [36]. |
| Edge Computing Module | A portable, low-power computer that performs real-time data processing and model inference at the deployment site. | NVIDIA Jetson Nano for executing CNN-LSTM models in the field [36]. |
Simultaneous multi-analyte detection in water bodies, powered by advanced sensor arrays and underpinned by the multi pseudo-calibration framework, is transforming environmental monitoring. The integration of diverse transduction mechanisms—electrochemical, acoustic, and optical—within a single platform enables the capture of a comprehensive water quality fingerprint that was previously inaccessible. The detailed protocols for multi-modal nano-sensors and acoustic e-tongues provide a tangible pathway for researchers to implement these technologies. As the field progresses, future challenges will include enhancing sensor longevity through antifouling coatings, improving model generalizability via federated learning, and creating self-calibrating monitoring networks using digital twins [36]. By adopting these sophisticated systems, the scientific community can advance towards a future of high-resolution, real-time water security surveillance, enabling proactive protection of global water resources.
Optimizing MPC Performance and Overcoming Practical Challenges
Strategies for Effective Pseudo-Calibration Sample Selection and Timing
Multi pseudo-calibration (MPC) represents a significant advancement in maintaining the accuracy of deeply-embedded sensor arrays used for continuous monitoring in pharmaceutical development and bioprocessing. Traditional sensor calibration methods require periodic recalibration using stable references, which is often not feasible in systems where sensors are integrated into bioreactors and uninterrupted monitoring is essential [3]. The MPC framework overcomes this limitation by treating periodic samples with offline analyte concentration analysis as "pseudo-calibration" points. These samples provide ground-truth data that enable continuous correction of sensor drift without process interruption. This application note details protocols for optimal pseudo-calibration sample selection and timing to maximize sensor data reliability throughout extended operational campaigns.
Theoretical Foundation of Multi Pseudo-Calibration
The MPC approach operates on the principle of leveraging historical sensor measurements and ground-truth data to construct a non-linear model of sensor drift [3]. When a ground-truth concentration from an offline analyzer becomes available for a past sample, the system treats this sample as a pseudo-calibration point. The fundamental innovation lies in the data augmentation process, where the input vector concatenates three critical elements: the difference between current sensor measurements and historical pseudo-calibration sample measurements, the ground-truth concentration for the pseudo-sample, and the temporal difference between measurements [3].
This approach offers three distinct advantages for pharmaceutical applications [3]:
- Non-linear drift modeling: Capability to learn complex, non-linear sensor drift patterns beyond simple linear corrections
- Quadratic data augmentation: Generating an augmented training set with N(N-1)/2 samples from an original set of N samples
- Variance reduction through ensemble prediction: When multiple pseudo-calibration samples are available, MPC generates predictions relative to each reference and averages results
Table 1: Core Advantages of MPC for Bioprocess Monitoring
| Advantage | Mechanism | Impact on Sensor Reliability |
|---|---|---|
| Non-linear Drift Modeling | Learns complex relationships between sensor outputs and environmental factors | Maintains accuracy under varying process conditions |
| Data Augmentation | Creates N(N-1)/2 training samples from N original samples | Enhances model robustness with limited ground-truth data |
| Variance Reduction | Averages predictions from multiple pseudo-calibration references | Improves measurement stability and confidence intervals |
Pseudo-Calibration Sample Selection Criteria
Representativeness of Process Conditions
Effective pseudo-calibration samples must capture the dynamic range of process conditions encountered during bioprocessing. Samples should be selected to represent the anticipated operational space, including varying analyte concentrations, temperature ranges, and humidity levels relevant to the specific bioprocess. For particulate matter monitoring in sterile environments, clustering algorithms such as Hierarchical Clustering and Mini-Batch K-Means have been successfully employed to classify particle size data and apply channel-specific correction factors [39]. This approach ensures that calibration accounts for the heterogeneous nature of particulates in pharmaceutical manufacturing environments.
Statistical Selection Approaches
For integrating large non-probability samples with smaller probability samples, pseudo-calibration estimators provide a robust statistical framework [40]. These estimators are particularly valuable when the target variable is observed correctly in probability samples but may be observed with error or predicted in non-probability samples. The methodology assumes that [40]:
- A reference survey with a probability sample exists where the target variable is observed correctly
- Units in the probability sample can be identified in the non-probability sample
- The non-probability sample contains auxiliary variables related to the target variable
Confidence-Based Filtering
In applications dealing with class-imbalanced data, confidence consistency filtering (CCF) provides a dynamic thresholding approach for pseudo-label selection [41]. This strategy generates thresholds based on data distribution rather than relying on static values, maximizing the inclusion of valid pseudo-labeled samples while maintaining quality. The approach is particularly valuable for increasing representation of minority class samples in diagnostic models, which translates well to pharmaceutical applications where certain process anomalies may be rare but critical to detect.
Timing Strategies for Pseudo-Calibration
Initial Establishment Phase
During the initial deployment of sensor arrays, pseudo-calibration samples should be collected at a higher frequency to establish baseline performance characteristics. Field validation studies for particulate matter sensors have demonstrated successful calibration models built from data collected over a 4-month initial monitoring period (March 1 to June 30) [39]. This initial phase should capture seasonal variations and process cycles relevant to the specific application.
Table 2: Pseudo-Calibration Timing Protocol for Different Process Phases
| Process Phase | Sample Frequency | Key Metrics | Validation Approach |
|---|---|---|---|
| Initial Establishment | High (e.g., daily) | Baseline accuracy, Environmental sensitivity | Correlation with reference methods (R² values) |
| Routine Operation | Reduced (e.g., weekly) | Drift patterns, Anomaly detection | Continuous performance monitoring against quality controls |
| Process Change | Increased (event-based) | Response dynamics, Recovery stability | Comparison pre/post change points |
Routine Operation and Process Changes
Once the initial calibration model is established, pseudo-calibration sampling frequency can be optimized based on observed sensor stability. However, the timing strategy should include event-based sampling triggered by process changes, suspected drift indicators, or scheduled maintenance activities. Research demonstrates that calibration parameters derived from an initial monitoring campaign can be successfully applied to subsequent monitoring periods (e.g., July 5 to September 15) [39], validating the stability of well-developed calibration models.
Adaptive Timing Based on System Observability
For complex multi-sensor systems, the timing of pseudo-calibration can be optimized using observability analysis. Recent frameworks enable pre-analysis of system performance to determine [42]:
- Observability of individual sensor systematic error states
- Minimum estimable values of sensor systematic error states
- Minimum detectable systematic errors in sensor observations
This approach allows for rigorous characterization of calibration performance during mission planning, before actual data collection.
Experimental Protocols for Pseudo-Calibration
Sensor Array Deployment and Configuration
Materials:
- Target sensor array (e.g., hydrogel-based magneto-resistive sensors) [3]
- Reference monitoring equipment (gold standard for ground truth)
- Data acquisition system with storage capability
- Environmental monitoring modules (temperature, humidity)
Procedure:
- Collocate sensor arrays with reference monitoring equipment in the operational environment
- Establish continuous data logging for all sensors and environmental parameters
- Define sampling intervals based on process dynamics and sensor response characteristics
- Implement redundant data storage to prevent loss of pseudo-calibration references
Pseudo-Calibration Sample Collection
Materials:
- Aseptic sampling equipment compatible with bioprocess systems
- Sample preservation materials as needed for offline analysis
- Chain-of-custody documentation for sample tracking
Procedure:
- Extract physical samples from the process stream at predetermined intervals
- Immediately analyze samples using reference methods (e.g., HPLC, mass spectrometry)
- Record precise timestamps for sample collection and analysis
- Document environmental conditions (temperature, humidity) and process parameters at sampling time
- Store results in structured database linking sensor data with ground-truth values
MPC Model Implementation
Materials:
- Computational infrastructure for machine learning implementation
- Data preprocessing tools for sensor data normalization
- Regression techniques (PLS, XGB, MLP) [3]
Procedure:
- Compile historical sensor measurements with associated ground-truth data
- Implement MPC input vector construction concatenating:
- Difference between current and pseudo-calibration sample sensor measurements
- Ground-truth concentration for pseudo-sample
- Time difference between measurements [3]
- Train regression models using the augmented dataset
- Validate model performance using holdout samples not included in training
- Deploy trained model for continuous sensor calibration during operation
Performance Validation
Materials:
- Independent validation samples with known concentrations
- Statistical analysis software for performance metrics
Procedure:
- Compare sensor outputs before and after pseudo-calibration application
- Calculate performance metrics including RMSE, MAE, and R² values
- Assess calibration stability over extended operational periods
- Verify system performance across entire measurement range
- Document any systematic biases remaining after calibration
Workflow Visualization
Research Reagent Solutions
Table 3: Essential Materials for Pseudo-Calibration Research
| Material/Reagent | Function | Application Context |
|---|---|---|
| Hydrogel-based magneto-resistive sensors | Continuous analyte monitoring | Bioreactor metabolite concentration tracking [3] |
| Reference analytical equipment (HPLC, MS) | Ground-truth concentration measurement | Offline sample analysis for pseudo-calibration [3] |
| Beta-ray attenuation monitors | Gold-standard particulate matter reference | Environmental monitoring in cleanroom facilities [39] |
| Temperature and humidity modules | Environmental parameter monitoring | Drift correlation analysis [39] |
| Data acquisition systems | Continuous sensor data logging | Temporal alignment of sensor and reference data [3] |
Effective pseudo-calibration sample selection and timing strategies are fundamental to maintaining sensor array accuracy in pharmaceutical applications. The multi pseudo-calibration approach provides a robust framework for continuous calibration without process interruption, leveraging strategically selected samples with ground-truth data to model and correct for sensor drift. By implementing the protocols outlined in this application note—including representativeness-based sample selection, confidence filtering, adaptive timing based on system observability, and rigorous validation—researchers can significantly enhance the reliability of sensor data throughout extended monitoring campaigns. These strategies enable more accurate process control and quality assurance in drug development applications where sensor stability is critical to product quality and patient safety.
Mitigating the Impact of Sensor Cross-Sensitivity on Model Accuracy
Sensor cross-sensitivity, the tendency of a sensor to respond to non-target gases, presents a fundamental challenge to the reliability of chemical sensor arrays in applications from environmental monitoring to pharmaceutical development [43] [44] [45]. This interference manifests in multiple ways: positive responses that create false alarms, negative responses that dangerously mask hazardous gases, and inhibition effects that prevent detection entirely [46] [45]. In complex environments like bioreactors, where sensors become deeply embedded and cannot be physically recalibrated, these effects accumulate as sensor drift, progressively degrading measurement accuracy over time [3].
The Multi Pseudo-Calibration (MPC) approach offers a transformative solution by treating periodic ground-truth measurements from offline analyzers as "pseudo-calibration" points [3]. This framework enables continuous on-site calibration without process interruption, strategically leveraging cross-sensitive responses as additional information features rather than treating them purely as noise. By constructing input vectors that concatenate differential sensor measurements, ground-truth concentrations, and temporal data, MPC learns non-linear drift patterns while quadratically expanding effective training data through sample pairing [3].
This application note details protocols for implementing MPC within cross-sensitive sensor arrays, providing researchers with structured methodologies to maintain model accuracy in long-term monitoring applications.
Understanding Cross-Sensitivity in Sensor Arrays
Fundamental Mechanisms
Cross-sensitivity originates from the underlying physics and chemistry of sensing technologies. In chemiresistive metal-oxide semiconductor (MOS) sensors, the primary mechanism involves oxygen adsorption on the material surface, where various gases interact with adsorbed oxygen ions, altering electrical resistance in ways that may overlap between target and non-target species [44]. For electrochemical sensors, cross-sensitivity occurs when gases other than the target analyte undergo oxidation or reduction at the working electrode, generating interfering current signals [46] [47].
Quantitative Cross-Sensitivity Profiles
The tables below summarize documented cross-sensitivity responses for common electrochemical and MOS sensors, illustrating the varying degrees of interference that must be accounted for in model development.
Table 1: Cross-Sensitivity of Electrochemical Sensors to Interfering Gases
| Target Gas | Interfering Gas | Concentration (ppm) | Apparent Reading | Response Type |
|---|---|---|---|---|
| Carbon Monoxide (CO) | Hydrogen (H₂) | 100 ppm | 24 ppm CO | Positive [46] |
| Carbon Monoxide (CO) | Nitric Oxide (NO) | 50 ppm | -16 ppm CO | Negative [46] |
| Chlorine (Cl₂) | Nitrogen Dioxide (NO₂) | 10 ppm | 20 ppm Cl₂ | Positive [46] |
| Chlorine (Cl₂) | Hydrogen Sulfide (H₂S) | 10 ppm | -12 ppm Cl₂ | Negative [46] |
| Ammonia (NH₃) | Hydrogen Sulfide (H₂S) | 25 ppm | 35 ppm NH₃ | Positive [46] |
| Sulfur Dioxide (SO₂) | Nitrogen Dioxide (NO₂) | 10 ppm | -16.5 ppm SO₂ | Negative [48] |
Table 2: Metal-Oxide Semiconductor Sensor Selectivity Ratios for Ammonia Detection
| Sensor Material | Target Gas | Interfering Gas | Response Ratio | Study Conditions |
|---|---|---|---|---|
| WO₃ | NH₃ | CH₄ | 7.3:1 | Controlled laboratory [49] |
| WO₃ | NH₃ | H₂S | 17.8:1 | Controlled laboratory [49] |
| SnO₂ | NH₃ | CH₄ | 3.2:1 | Controlled laboratory [49] |
The Multi Pseudo-Calibration Framework
Core Architecture
The MPC approach constructs an augmented feature space that transforms cross-sensitivity from a liability into a source of discriminative information. When a ground-truth measurement becomes available at time t, the system generates feature vectors that combine:
- Differential sensor signals between current measurements and pseudo-calibration points
- Absolute ground-truth concentrations from offline analysis
- Temporal metadata including time since calibration and environmental conditions [3]
This input formulation enables machine learning models to learn the complex, non-linear relationships between sensor drift, environmental parameters, and actual analyte concentrations.
Workflow Implementation
The following diagram illustrates the integrated MPC workflow for handling cross-sensitive data streams:
Diagram 1: MPC workflow for cross-sensitive sensor data processing. The system integrates continuous sensor measurements with periodic ground-truth samples to generate drift-compensated predictions.
Experimental Protocols for MPC Implementation
Sensor Array Configuration and Baseline Characterization
Objective: Establish baseline performance metrics and cross-sensitivity profiles for all sensors in the array prior to deployment.
Materials:
- Sensor array with mixed sensing technologies (e.g., MOS, electrochemical)
- Precision gas delivery system with mass flow controllers
- Zero air source and standard gas cylinders (target and potential interferents)
- Environmental chamber for temperature and humidity control
- Data acquisition system with minimum 16-bit resolution
Procedure:
- Sensor Conditioning: Operate sensors under recommended operating conditions for 48 hours to stabilize baseline signals.
- Single-Gas Response Characterization:
- Expose array to target gas at 5 concentration levels across expected operating range
- Record steady-state responses with triplicate measurements at each concentration
- Calculate sensitivity, linearity, and limit of detection for each sensor-target pair
- Cross-Sensitivity Mapping:
- For each target gas, systematically expose array to potential interferents
- Maintain interferent concentrations within expected environmental ranges
- Record both steady-state and transient responses
- Environmental Testing:
Data Analysis:
- Construct cross-sensitivity matrix similar to Table 1 for all sensor-gas combinations
- Calculate selectivity coefficients for primary target gases against major interferents
- Establish normalization procedures for environmental effects
MPC-Specific Workflow Implementation
Objective: Implement the complete MPC cycle for continuous monitoring with periodic ground-truth updates.
Materials:
- Fully characterized sensor array from Protocol 4.1
- Bioreactor or continuous monitoring system
- Offline analytical capability (e.g., GC-MS, HPLC, reference analyzer)
- Data processing infrastructure with ML capabilities
Procedure:
- Initial Model Training:
- Collect sensor array data under known conditions
- Train initial regression models (PLS, XGB, MLP) using pre-deployment data
- Establish baseline prediction accuracy for target analytes
Pseudo-Calibration Sampling:
- Extract physical samples at predetermined intervals (e.g., every 24-72 hours)
- Analyze using reference method to obtain ground-truth concentrations
- Record precise timestamp and environmental conditions for each sample
Feature Augmentation:
- For each new sensor reading, create paired samples with all previous pseudo-calibration points
- Calculate differential signals: ΔS = Scurrent - Spseudo-cal
- Incorporate ground-truth values and time differentials into feature vectors
Model Update:
- Retrain models using augmented dataset with all historical pseudo-calibration points
- Implement weighted sampling to balance recent and historical data
- Validate model performance against most recent ground-truth measurements
Continuous Operation:
- Generate predictions using current sensor data relative to multiple pseudo-calibration points
- Average predictions from different reference points to reduce variance [3]
- Monitor model performance metrics and trigger alerts for deviations
Validation and Performance Assessment
Objective: Quantify MPC effectiveness in mitigating cross-sensitivity effects compared to conventional approaches.
Materials:
- Independent test dataset with known concentrations
- Statistical analysis software
- Benchmark models (standard regression, DCAE method)
Procedure:
- Experimental Design:
- Collect continuous sensor data under conditions with known interferent variations
- Obtain frequent ground-truth measurements for validation (not used in training)
- Introduce controlled interferent pulses to challenge the system
Performance Metrics:
- Calculate RMSE, R², and MAE for concentration predictions
- Quantify false positive/negative rates for threshold-based detection
- Assess long-term drift by comparing prediction accuracy over time
Comparative Analysis:
- Benchmark MPC against standard regression without pseudo-calibration
- Compare with state-of-the-art methods (e.g., Drift Correction Autoencoders)
- Evaluate computational requirements and scalability
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Research Materials for Cross-Sensitivity Mitigation Studies
| Category | Specific Items | Research Function | Key Considerations |
|---|---|---|---|
| Sensor Technologies | Metal-oxide semiconductors (WO₃, SnO₂, ZnO) [44] [49] | Primary sensing elements for target analytes | Select based on binding energy to target gases [49] |
| Electrochemical sensors (Alphasense B4 series) [47] | Low-power gas monitoring | Cross-sensitivity varies by manufacturer and age [48] | |
| Calibration Systems | Precision gas generators with mass flow controllers [49] | Generating known concentration mixtures | Requires capability for multi-gas blending |
| Zero air sources and standard gas cylinders | Baseline establishment and reference points | Purity requirements depend on target concentrations | |
| Computational Tools | Partial Least Squares (PLS) regression [3] | Baseline multivariate calibration | Linear method, limited for complex non-linearities |
| Extreme Gradient Boosting (XGB) [3] [50] | Handling complex feature interactions | Robust to outliers, good for tabular sensor data | |
| Multi-Layer Perceptrons (MLP) [3] | Modeling non-linear drift patterns | Requires careful architecture design and regularization | |
| Convolutional Neural Networks (CNN) [44] [49] | Pattern recognition in sensor array data | Effective for temporal response patterns [49] | |
| Reference Analytics | Gas chromatograph-mass spectrometer (GC-MS) | Gold-standard concentration validation | Provides definitive ground-truth for pseudo-calibration |
| Optical reference analyzers (e.g., NDIR) [47] | Continuous performance validation | Useful for co-location during field deployment |
Advanced Integration: Sensor Arrays and Machine Learning Synergies
Strategic sensor array design significantly enhances MPC effectiveness. Research demonstrates that combining sensors with complementary cross-sensitivity profiles creates more discriminative response patterns. For example, WO₃-based sensors exhibit strong NH₃ selectivity with binding energy of -1.45 eV compared to -1.10 eV for SnO₂, enabling better discrimination from interferents like CH₄ and H₂S [49].
The emerging approach of algorithm-material co-design optimizes both physical sensor properties and computational methods simultaneously. A quasi-2D sensor array with strategically selected metal oxides (WO₃, ZnO) improved NH₃ classification accuracy to 96.4%—a 7.2% increase over conventional arrays—while reducing concentration errors by 50.8% [49]. When integrated with CNN architectures specifically designed to extract temporal response patterns, these co-designed systems achieved 91.7% accuracy in mixed-gas environments despite significant cross-sensitivity at the individual sensor level [49].
For computational implementation, the MPC framework has demonstrated effectiveness across multiple regression techniques, with studies reporting:
- PLS-MPC: Most effective for linear response systems with moderate drift
- XGB-MPC: Superior performance for complex, non-linear drift patterns with interacting environmental factors [3]
- MLP-MPC: Capable of learning complex non-linear relationships but requires larger training datasets
Environmental factors, particularly humidity and temperature, introduce significant variability in cross-sensitivity effects. Successful MPC implementations incorporate weighted least squares error propagation models to quantify measurement uncertainties under varying conditions (30-90% RH, 10-40°C), achieving uncertainty bounds of ±8% for agricultural NH₃ monitoring [49].
Continuous monitoring with chemical sensor arrays is indispensable in modern pharmaceutical development and healthcare, enabling real-time tracking of critical biomarkers and process variables. However, the utility of these sensors is fundamentally compromised by time-dependent drift and aging effects, which degrade sensing performance and lead to inaccurate quantification of target analytes over time [3]. In applications such as bioprocess monitoring, where sensors are deeply embedded within bioreactors, traditional periodic recalibration using reference solutions is not feasible without interrupting the ongoing process [3].
To address this challenge, the Multi Pseudo-Calibration (MPC) approach has been developed as a novel on-site calibration methodology. A particularly innovative aspect of MPC is its ability to generate a Quadratic Data Augmentation Effect through intelligent sample pairing. This technique leverages previously acquired sensor measurements and their corresponding ground-truth concentrations to dramatically expand the effective training dataset, enabling the system to learn complex, non-linear drift patterns without process interruption [3].
This article presents comprehensive application notes and experimental protocols for implementing quadratic data augmentation through sample pairing within MPC frameworks, specifically tailored for pharmaceutical research and development applications.
Theoretical Foundation: Multi Pseudo-Calibration (MPC)
Core Principles of MPC
The Multi Pseudo-Calibration approach operates on the fundamental premise that periodically extracted samples from a bioreactor or similar system can be analyzed using offline analyzers to obtain ground-truth concentrations. These samples subsequently serve as "pseudo-calibration" points that provide additional information for regression models [3].
The MPC framework constructs an input vector that concatenates three critical elements:
- The difference between current sensor measurements and sensor measurements for the pseudo-calibration sample
- The ground-truth concentration for the pseudo-sample
- The time difference between current and pseudo-calibration measurements
This integrated approach allows the system to continuously adapt to sensor drift while maintaining operational continuity in environments where traditional calibration is impossible.
The Quadratic Augmentation Mechanism
The most mathematically profound aspect of MPC lies in its quadratic data augmentation effect. Given a training set with N samples, the sample pairing methodology enables each sample to be paired with any previous sample, resulting in an augmented training set with N(N-1)/2 distinct data points [3]. This quadratic expansion effectively multiplies the utility of each collected sample, addressing the fundamental challenge of data scarcity in complex biological systems.
Table 1: Quadratic Growth of Training Data Through Sample Pairing
| Number of Original Samples (N) | Number of Augmented Samples (N(N-1)/2) | Expansion Factor |
|---|---|---|
| 10 | 45 | 4.5× |
| 50 | 1,225 | 24.5× |
| 100 | 4,950 | 49.5× |
| 200 | 19,900 | 99.5× |
Experimental Protocols for MPC Implementation
Sensor Array Configuration and Data Collection
Protocol 1: Establishing Baseline Sensor Performance
- Sensor Selection: Deploy an array of cross-sensitive chemical sensors appropriate for the target analytes. Hydrogel-based magneto-resistive sensors have demonstrated effectiveness in bioprocess monitoring applications [3].
- Baseline Characterization: Collect initial sensor measurements across expected operating conditions to establish baseline performance metrics.
- Reference Sampling: Implement a systematic protocol for periodic extraction of samples from the bioreactor for offline analysis. Record exact timestamps for each sample extraction.
- Ground-Truth Analysis: Utilize reference analytical methods (e.g., HPLC, mass spectrometry) to determine precise analyte concentrations for each extracted sample.
- Data Storage: Maintain a comprehensive database storing all sensor measurements with corresponding timestamps and ground-truth concentrations when available.
Protocol 2: Implementing Sample Pairing for Quadratic Augmentation
- Data Structure Preparation: Organize collected data into tuples containing (sensormeasurements, groundtruth_concentration, timestamp).
- Pair Generation Algorithm: Implement an algorithm that systematically pairs each data sample with all chronologically previous samples.
- Input Vector Construction: For each sample pair (i, j) where j < i, construct an input vector containing:
- Δsensor = sensormeasurementsi - sensormeasurementsj
- groundtruthconcentration_j
- Δtime = timestampi - timestampj
- Target Variable Assignment: The target variable for each pair is the ground-truth concentration corresponding to the more recent sample (sample i).
Model Training and Validation
Protocol 3: Regression Model Implementation with MPC
- Model Selection: Choose appropriate regression techniques. Partial least squares (PLS), extreme gradient boosting (XGB), and multi-layer perceptrons (MLPs) have been successfully implemented with MPC [3].
- Training Configuration: Configure models to accept the augmented input vectors and predict current analyte concentrations.
- Cross-Validation: Implement leave-one-probe-out cross-validation techniques, using 3 of 4 probes for training and the remaining probe for testing, repeated 4 times [3].
- Drift Evaluation: Split each probe's dataset into two segments with a 75/25 split, using the first 75% of measurements for training and the last 25% for testing to evaluate drift compensation performance [3].
- Ensemble Prediction: When multiple pseudo-calibration samples are available, generate predictions relative to each sample and average the results to reduce prediction variance.
Table 2: Performance Comparison of Regression Techniques with MPC
| Regression Technique | Baseline Performance (Without MPC) | Performance with MPC | Key Advantages |
|---|---|---|---|
| Partial Least Squares (PLS) | Baseline accuracy | 12-18% improvement in imputation accuracy [51] | Computational efficiency, stability |
| Extreme Gradient Boosting (XGB) | Baseline accuracy | 31% reduction in electricity costs [52] | Handling non-linear relationships, feature importance |
| Multi-Layer Perceptron (MLP) | Baseline accuracy | 46% reduction in GHG emissions [52] | High capacity for complex patterns, adaptability |
| ReLU Neural Networks | Baseline accuracy | 76.25% average Dice Similarity Coefficient [53] | Theoretical guarantees, constraint satisfaction |
Advanced Applications in Pharmaceutical Development
Bioprocess Monitoring and Optimization
The MPC approach with quadratic data augmentation has demonstrated significant utility in biopharmaceutical manufacturing, where precise monitoring of nutrient concentrations, metabolites, and product titers is essential for process control and quality assurance.
Protocol 4: Bioreactor Monitoring Implementation
- Sensor Integration: Embed cross-sensitive chemical sensor arrays at critical locations within the bioreactor system.
- Sampling Schedule: Establish a predetermined schedule for sample extraction based on process criticality points (e.g., during exponential growth phase, nutrient depletion, or product induction).
- Rapid Offline Analysis: Implement high-throughput analytical methods to minimize delay between sample extraction and availability of ground-truth data.
- Real-Time Model Updates: Incorporate new pseudo-calibration points as ground-truth data becomes available, continuously refining the drift compensation model throughout the process cycle.
- Anomaly Detection: Monitor model residuals to identify process deviations or sensor failures in real-time.
Drug Formulation and Stability Studies
Quadratic data augmentation through sample pairing enables unprecedented precision in long-term stability studies, where sensor drift would otherwise compromise data integrity over extended durations.
Protocol 5: Accelerated Stability Testing
- Multi-Analyte Monitoring: Deploy sensor arrays capable of simultaneously monitoring active pharmaceutical ingredient (API) concentration, degradation products, and critical excipients.
- Forced Degradation Samples: Intentionally expose subset samples to accelerated degradation conditions (elevated temperature, humidity, light) to generate diverse reference points.
- Reference Method Correlation: Establish correlation between sensor readings and reference USP/Ph.Eur. analytical methods for each analyte.
- Predictive Modeling: Leverage the expanded dataset to develop predictive models of product stability under various environmental conditions.
Research Reagent Solutions and Materials
Table 3: Essential Research Reagents and Materials for MPC Implementation
| Item | Specification | Function in MPC Protocol |
|---|---|---|
| Cross-sensitive chemical sensor array | Hydrogel-based magneto-resistive sensors [3] | Primary sensing element for continuous monitoring of multiple analytes |
| Reference standard materials | Certified reference materials for target analytes | Establishing ground-truth concentrations for pseudo-calibration points |
| Mobile phase reagents | HPLC-grade solvents and buffers | Offline analysis of extracted samples for ground-truth determination |
| Bioreactor system | Standard laboratory or production-scale bioreactor | Controlled environment for process monitoring applications |
| Data acquisition system | High-precision analog-to-digital converters | Accurate recording of sensor array measurements with precise timestamping |
| Calibration solutions | Known concentrations of target analytes in relevant matrix | Initial sensor calibration and periodic performance verification |
Performance Validation and Quality Control
Validation Protocols
Protocol 6: MPC System Performance Verification
- Accuracy Assessment: Compare MPC-predicted concentrations against held-out ground-truth measurements using mean absolute percentage error (MAPE) and root mean square error (RMSE) metrics.
- Drift Compensation Evaluation: Monitor long-term performance stability by comparing prediction accuracy between early and late process stages.
- Robustness Testing: Evaluate system performance under varying process conditions to ensure generalizability.
- Comparison to Alternatives: Benchmark MPC performance against state-of-the-art drift-correction methods such as Drift Correction Autoencoders (DCAE) [3].
Troubleshooting Common Implementation Challenges
Challenge 1: Insufficient Sample Diversity
- Solution: Implement intentional variation in process parameters during initial data collection to ensure adequate coverage of potential operating conditions.
Challenge 2: Temporal Alignment Issues
- Solution: Implement precise timestamping with synchronization across all sensors and analytical instruments.
Challenge 3: Model Degradation Over Extended Operations
- Solution: Establish criteria for model retraining and implement automated performance monitoring with alert triggers.
The Quadratic Data Augmentation Effect achieved through sample pairing in Multi Pseudo-Calibration represents a significant advancement in continuous monitoring applications for pharmaceutical development. By transforming the fundamental challenge of sensor drift into an opportunity for dataset expansion, this approach enables unprecedented accuracy and reliability in long-term monitoring scenarios where traditional calibration is impossible.
The structured protocols and application notes presented herein provide researchers with a comprehensive framework for implementing this powerful methodology across diverse pharmaceutical applications, from upstream bioprocess monitoring to downstream formulation and stability studies. As sensor technologies continue to evolve and computational methods advance, the integration of quadratic data augmentation principles with emerging analytical techniques promises to further enhance capabilities in real-time process analytical technology (PAT) and quality-by-design (QbD) initiatives.
Hyperparameter Tuning for Underlying Regression Models (PLS, XGB, MLP)
Within the framework of multi pseudo-calibration (MPC) for advanced sensor arrays, the stability and predictive performance of underlying regression models are paramount. The MPC approach often relies on synthesizing signals from multiple sensor elements, requiring regression techniques that are robust to multicollinearity and high-dimensional data. This document provides detailed application notes and experimental protocols for tuning three fundamental regression models: Partial Least Squares (PLS), eXtreme Gradient Boosting (XGBoost), and Multilayer Perceptron (MLP). The guidance is specifically tailored for researchers and scientists developing calibration models for sensor systems in pharmaceutical and diagnostic applications.
Model-Specific Hyperparameter Tuning
Partial Least Squares (PLS) Regression
PLS regression is a dimensionality reduction technique that is particularly effective for handling correlated predictor variables, a common scenario in sensor array data where multiple sensors may capture related information [54] [55]. Unlike Principal Components Regression (PCR), which selects components based solely on input variance, PLS explicitly incorporates the response variable during component construction, making it often more predictive for a given number of components [54].
Key Hyperparameters and Tuning Protocol
Table 1: Core Hyperparameters for PLS Regression
| Hyperparameter | Description | Recommended Tuning Range | Impact on Model |
|---|---|---|---|
ncomp |
Number of PLS components to retain | 1 to number of predictors [54] | Controls complexity; too few components underfit, too many may overfit |
scale |
Whether to standardize variables (mean-center and unit variance) | Boolean (TRUE/FALSE) [55] | Essential when variables have different units of measurement |
validation |
Type of validation method for selecting components | "CV" for cross-validation [56] | Determines reliability of component selection |
method |
Algorithm used for PLS computation | "kernelpls", "simpls", or "oscorespls" [55] | Affects computation speed and results in high-dimensional spaces |
Experimental Protocol for PLS Tuning:
- Preprocessing: Center and scale all predictor variables to zero mean and unit variance, as PLS is sensitive to variable scale [55].
- Component Selection: Use k-fold cross-validation (typically k=5 or 10) to evaluate model performance with increasing numbers of components. The
tune()function in themixOmicsR package is specifically designed for this purpose [56]. - Optimal Number: Plot cross-validated prediction error (e.g., RMSE) against the number of components. Select the point where the error curve flattens or begins to increase, indicating diminishing returns or overfitting [54].
- Validation: Assess the final model on a held-out test set to estimate generalization performance.
eXtreme Gradient Boosting (XGBoost) Regression
XGBoost is a powerful tree-based ensemble algorithm that excels at capturing complex, non-linear relationships in data, which may be beneficial for modeling intricate sensor response patterns. Its performance heavily depends on proper hyperparameter configuration to balance model complexity and generalization [57] [58].
Key Hyperparameters and Tuning Protocol
Table 2: Core Hyperparameters for XGBoost Regression
| Hyperparameter | Description | Recommended Tuning Range | Impact on Model |
|---|---|---|---|
max_depth |
Maximum depth of a tree [58] [59] | 3 to 12 [59] | Controls complexity; deeper trees capture more interactions but risk overfitting |
learning_rate (eta) |
Step size shrinkage [58] [59] | 0.001 to 0.3 [58] [59] | Lower values require more rounds but can lead to better generalization |
subsample |
Proportion of training data used for each tree [58] [59] | 0.7 to 1.0 [59] | Introduces randomness to prevent overfitting |
colsample_bytree |
Proportion of features used for each tree [58] [59] | 0.5 to 1.0 [59] | Controls feature-level randomization |
reg_lambda |
L2 regularization term on weights [58] [59] | 0 to 10 [59] | Penalizes large weights to reduce overfitting |
min_child_weight |
Minimum sum of instance weight needed in a child node [58] [59] | 1 to 200 [59] | Controls tree partitioning; higher values make the model more conservative |
n_estimators |
Number of boosting rounds [58] | 50 to 2000 (use early stopping) [59] | More rounds can improve performance up to a point |
Efficient Two-Stage Tuning Protocol for XGBoost [59]:
- Tune Tree Parameters: Fix the learning rate at a moderately high value (e.g., 0.1-0.3) and use early stopping. Employ Bayesian optimization (e.g., via Optuna) or random search to find optimal tree-specific parameters (
max_depth,min_child_weight,subsample,colsample_bytree,reg_lambda). - Tune Boosting Parameters: With the optimal tree parameters fixed, lower the learning rate (e.g., to 0.01 or 0.001) and use early stopping to determine the optimal number of boosting rounds. This leverages the finding that good tree parameters are generally transferable across learning rates [59].
Multilayer Perceptron (MLP) Regression
MLP or fully connected neural networks can model highly complex non-linear relationships in sensor data. Their flexibility requires careful regularization and architecture tuning to prevent overfitting, especially with the limited dataset sizes common in sensor calibration [60].
Key Hyperparameters and Tuning Protocol
Table 3: Core Hyperparameters for MLP Regression
| Hyperparameter | Description | Recommended Tuning Range | Impact on Model |
|---|---|---|---|
hidden_layer_sizes |
Number and size of hidden layers [60] | (50,50,50), (50,100,50), (100,) [61] | Controls network capacity; deeper/wider networks can learn more complex functions |
activation |
Non-linear activation function [60] | 'relu', 'tanh', 'logistic' [61] | 'relu' avoids vanishing gradients; 'tanh' can be more expressive |
alpha |
L2 regularization parameter [61] | 0.0001 to 0.05 [61] | Penalizes large weights to prevent overfitting |
learning_rate_init |
Initial learning rate [60] | 0.001, 0.01 [60] | Affects convergence speed and stability |
batch_size |
Number of samples per gradient update [60] | 32, 64, 128 (powers of 2) [60] | Smaller batches can regularize through noise |
max_iter |
Maximum number of epochs [61] | 1000+ (with early stopping) [61] | Prevents indefinite training; use early stopping to halt when validation score stops improving |
solver |
Weight optimization algorithm [61] [60] | 'adam', 'lbfgs', 'sgd' [61] | 'adam' works well for most problems with adaptive learning rates |
Experimental Protocol for MLP Tuning:
- Architecture Search: Begin with a modest architecture (1-2 hidden layers) and gradually increase complexity if performance is inadequate. Use random search or Bayesian optimization over the hyperparameter space.
- Address Convergence: If encountering convergence warnings, increase
max_iterto 5000 or higher, experiment withbatch_size(e.g., 16, 32, 64), or slightly increase the initial learning rate [61]. - Regularization: Systematically test L2 regularization (
alpha) and consider adding dropout (if available in your implementation) to combat overfitting. - Early Stopping: Implement early stopping based on a validation set to automatically determine the optimal number of epochs and prevent overtraining [60].
The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential Software Tools for Regression Model Tuning
| Tool/Platform | Primary Function | Application in MPC Sensor Research |
|---|---|---|
caret (R) / scikit-learn (Python) |
Unified interface for model training and tuning [54] [62] | Provides standardized implementations of PLS, MLP, and tuning methods for reproducible research |
mixOmics (R) |
Specialized package for PLS and related methods [56] | Offers the tune() function for efficient parameter tuning of PLS models in high-dimensional sensor data |
XGBoost (Python/R) |
Scalable gradient boosting library [57] [58] | Handles complex non-linear relationships in multi-sensor array data with high performance |
Optuna / Hyperopt |
Bayesian optimization frameworks [58] [59] | Enables efficient hyperparameter search for all three models, reducing computational time and resources |
TensorFlow/Keras (Python) |
Deep learning frameworks [60] | Provides flexible implementation of MLP architectures with various regularization options |
Integrated Tuning Workflow for MPC Sensor Arrays
Developing a robust MPC model requires a systematic approach to tuning the underlying regression algorithms. The following integrated workflow ensures optimal model performance while maintaining computational efficiency.
Integrated Protocol:
- Data Stratification: Split sensor array data into training (60-70%), validation (15-20%), and test (15-20%) sets, preserving the distribution of critical experimental factors.
- Model Selection: Choose the regression approach based on data characteristics:
- PLS: Preferred when predictors are highly correlated or when interpretability of component weights is important [54] [55].
- XGBoost: Optimal for capturing complex, non-linear relationships and interaction effects between sensor signals [58] [59].
- MLP: Suitable when data exhibits deep hierarchical patterns that simpler models cannot capture [60].
- Parallel Tuning: Execute the model-specific tuning protocols described in Sections 2.1-2.3 simultaneously.
- Final Evaluation: Compare the performance of all tuned models on the held-out test set using appropriate metrics (RMSE, R², MAE) relevant to the MPC application.
- Model Interpretation: Analyze feature importance (PLS loadings, XGBoost feature gains, MLP sensitivity analysis) to validate the biological/chemical relevance of the selected model for the sensor application.
This structured approach to hyperparameter tuning ensures that MPC models for sensor arrays achieve optimal performance while maintaining interpretability and robustness required for pharmaceutical and diagnostic applications.
In sensor arrays research, particularly within pharmaceutical and bioprocess monitoring, time-dependent drift poses a significant challenge to data integrity and predictive accuracy. This drift degrades sensor performance, leading to inaccurate identification or quantification of target analytes over extended operational periods [3]. The multi pseudo-calibration (MPC) approach introduces a robust framework for on-site calibration that leverages historical ground-truth measurements as pseudo-calibration points. A core strength of this methodology lies in its strategic use of prediction averaging across multiple reference points, which effectively reduces variance and enhances the reliability of sensor readings in environments where traditional recalibration is impractical [3].
This Application Note details the theoretical foundation, experimental protocols, and practical implementation of averaging predictions within the MPC framework, providing researchers and drug development professionals with a structured guide for mitigating sensor variance.
Theoretical Foundation of MPC
The multi pseudo-calibration (MPC) approach is designed to compensate for sensor drift without interrupting continuous monitoring processes, such as those in bioreactors [3].
Core Principle and Mechanism
MPC operates on the principle that any past sensor measurement with a known ground-truth concentration can serve as a "pseudo-calibration" point. When a new sensor measurement is taken, the model does not use the raw sensor data directly. Instead, it constructs an input vector that includes:
- The difference between the current sensor readings and the sensor readings from each pseudo-calibration sample.
- The ground-truth concentration for the pseudo-calibration sample.
- The time difference between the current measurement and the pseudo-calibration time [3].
This input structure allows the underlying regression model to learn a non-linear model of the sensor drift.
Mathematical Workflow and Variance Reduction
The power of averaging emerges from the MPC's data handling. For a training set with N samples, each sample can be paired with any previous sample, creating an augmented training set with N(N-1)/2 samples [3]. This quadratic increase in data volume provides a richer foundation for model training.
When multiple pseudo-calibration samples are available, the MPC framework generates a separate prediction for the current measurement relative to each of these past references. The final, stabilized prediction is the average of these individual predictions. This process of averaging multiple predictions significantly reduces the variance of the final output, leading to more robust and reliable measurements [3]. The following diagram illustrates this workflow.
Experimental Protocols for MPC Implementation
This section provides a detailed, step-by-step protocol for implementing and validating the MPC approach with prediction averaging.
Protocol: Implementing MPC with Averaging
Objective: To configure an MPC pipeline that utilizes multiple pseudo-calibration points and averages their predictions to output a final, variance-reduced result.
Step 1: Data Collection and Preprocessing
- Continuously collect time-series data from the chemical sensor array deployed in the process (e.g., a bioreactor).
- Periodically, extract physical samples and obtain ground-truth analyte concentrations using an offline analyzer (e.g., HPLC, mass spectrometry). Record the timestamp for each ground-truth sample.
Step 2: Data Structure Preparation
- For each new sensor measurement
S_newat timet_new, identify all available historical pseudo-calibration points. Each pointiconsists of a pair of sensor measurementsS_iand the corresponding ground-truth concentrationC_iat timet_i. - For each pseudo-calibration point
i, construct an input vectorX_ias follows:X_i = [ (S_new - S_i), C_i, (t_new - t_i) ]
- The corresponding target output
Yfor model training is the ground-truth concentrationC_newassociated withS_new(when available for training).
- For each new sensor measurement
Step 3: Model Training and Prediction Generation
- Train a chosen regression model (e.g., PLS, XGBoost, MLP) using the augmented dataset of all constructed input vectors
X_iand their targetsY. - In production (inference mode), for a new measurement
S_new, use every available pseudo-calibration pointito create an input vectorX_i. - Pass each
X_ithrough the trained model to generate an individual predicted concentrationP_i.
- Train a chosen regression model (e.g., PLS, XGBoost, MLP) using the augmented dataset of all constructed input vectors
Step 4: Averaging Predictions
- Collect the set of all individual predictions
{P_1, P_2, ..., P_k}generated from thekavailable pseudo-calibration points. - Compute the final predicted concentration
P_finalby calculating the arithmetic mean of allP_i. P_final = (P_1 + P_2 + ... + P_k) / k
- Collect the set of all individual predictions
Protocol: Experimental Validation of Averaging Efficacy
Objective: To quantitatively demonstrate the variance reduction achieved through prediction averaging in an MPC setup.
Step 1: Experimental Setup
- Utilize an experimental dataset from a cross-sensitive sensor array, such as hydrogel-based magneto-resistive sensors for bioprocess monitoring [3].
- Alternatively, employ a synthetic dataset that allows for controlled introduction of sensor cross-sensitivity and non-linear drift.
Step 2: Evaluation Procedure
- Apply a leave-one-probe-out cross-validation technique. Use data from 3 of 4 sensor probes for training and the remaining probe for testing, repeating the process for all combinations [3].
- To emphasize drift effects, split each probe's data temporally: use the first 75% for training and the last 25% for testing.
Step 3: Comparative Analysis
- Train and evaluate three different models implementing MPC with averaging: Partial Least Squares (PLS), Extreme Gradient Boosting (XGB), and Multi-Layer Perceptrons (MLP) [3].
- Compare their performance against two baselines:
- Baseline 1: A standard regression model (PLS, XGB, MLP) that uses only current sensor measurements without pseudo-calibration.
- Baseline 2: A state-of-the-art drift-correction method like the Drift Correction Autoencoder (DCAE) [3].
Step 4: Performance Metrics
- Quantify performance using Mean Squared Error (MSE) or Root Mean Squared Error (RMSE) between the predicted and ground-truth concentrations.
- Calculate the variance of the individual predictions
{P_1, P_2, ..., P_k}for each sample in the test set. Compare this to the variance of the error of the final averaged prediction to demonstrate stabilization.
The following workflow maps the experimental validation process.
Expected Results and Data Presentation
Implementation of the MPC approach with averaging is expected to yield a significant reduction in prediction error compared to baseline methods. The following table summarizes typical outcomes.
Table 1: Comparative Performance of MPC with Averaging Against Baseline Methods
| Model / Method | Key Feature | Training MSE | Test MSE | Variance of Predictions |
|---|---|---|---|---|
| PLS (Baseline) | Standard regression, no drift compensation | Not Reported | Not Reported | High |
| XGB (Baseline) | Standard regression, no drift compensation | Not Reported | Not Reported | High |
| DCAE (Baseline) | State-of-the-art drift correction | Not Reported | Not Reported | Medium |
| MPC-PLS | Uses pseudo-calibration & averaging | Low | Low | Low |
| MPC-XGB | Uses pseudo-calibration & averaging | Low | Low | Low |
| MPC-MLP | Uses pseudo-calibration & averaging | Low | Low | Low |
Note: Specific MSE values are dependent on the dataset and drift severity. The MPC approach consistently shows lower error and variance than its non-MPC counterpart and other baselines [3].
The efficacy of averaging is further illuminated by examining the performance on a low-cost sensor array, where a deep learning framework can enhance precision.
Table 2: Performance of a Deep Learning Model on a Low-Cost Sensor Array
| Dataset | Model | Training Loss (MSE) | Test Loss (MSE) | Key Achievement |
|---|---|---|---|---|
| 32-Sensor Array (16 Analog, 16 Digital) | Deep Neural Network (DNN) | 1.47x10⁻⁴ | 1.22x10⁻⁴ | Significant precision and accuracy enhancement of low-accuracy sensors [63] |
Advanced Applications and Integration
The MPC framework with prediction averaging can be integrated with other advanced computational techniques to further bolster sensor array reliability.
- Integration with Collaborative Filtering: In large-scale IoT sensor networks, sensor failures are inevitable, leading to missing data. Collaborative Filtering (CF) techniques, commonly used in recommender systems, can predict these missing readings by leveraging correlations in the data from all sensors in the network [64]. The MPC-averaged predictions from functioning sensors can serve as high-quality input for these CF models, creating a robust hybrid system for data integrity.
- Deep Learning for Enhanced Precision: As demonstrated in Table 2, deep neural networks can be applied to the data from an array of low-cost, low-accuracy sensors to dramatically improve the precision and accuracy of their readings [63]. This approach can be used as a preprocessing step before the MPC model, ensuring that the input data for pseudo-calibration is of the highest possible quality.
The Scientist's Toolkit
Table 3: Essential Research Reagent Solutions and Materials
| Item | Function / Application |
|---|---|
| Cross-Sensitive Chemical Sensor Array | The core sensing unit; provides multidimensional data for multiple analytes. Example: Hydrogel-based magneto-resistive sensors for bioprocess monitoring [3]. |
| Offline Analyzer | Provides ground-truth concentration data for pseudo-calibration samples. Examples include HPLC systems, mass spectrometers, or other certified analytical instruments [3]. |
| Low-Cost Sensor Array | An array of inexpensive sensors (e.g., 32 temperature sensors with 0.5-2.0°C accuracy) for validating precision-enhancement methodologies [63]. |
| Regression Model Software | Software environments (e.g., Python with Scikit-learn, XGBoost, TensorFlow/PyTorch) for implementing PLS, XGB, MLP, and DNN models [3] [63]. |
| Collaborative Filtering Library | Software libraries (e.g., Python Surprise, implicit) for implementing matrix factorization and K-NN methods to recover missing sensor data in large networks [64]. |
| Data Acquisition System | A system (e.g., microcontroller like Arduino Mega) to collect and record time-synchronized data from all sensors in the array [63]. |
The multi pseudo-calibration (MPC) approach for sensor arrays aims to enhance measurement reliability by leveraging data from multiple sources and standards. A significant barrier to the widespread adoption of this technology, particularly in clinical and demanding environments, is the intrinsic variability of both sensors and real-world samples. This application note details how the use of synthetic calibration standards provides a robust solution to these challenges, ensuring reproducibility and facilitating effective calibration transfer across sensor platforms.
Quantitative Data Synthesis
The following tables consolidate key quantitative findings from experimental studies on calibration transfer and sensor performance.
Table 1: Performance Metrics of Calibration Transfer Using Synthetic Standards
| Study Focus | Performance without CT | Performance with CT (Direct Standardization) | Key Transfer Samples Used |
|---|---|---|---|
| Urine Headspace Analysis with E-Noses [65] | Classification accuracy decreased to 37-55% | Accuracy restored to 75-80% | Synthetic urine recipes mimicking sensor responses |
| Self-X TMR Sensor Array [66] | Single sensor MAE: 1.749° to 5.632° | MAE reduced by >80%; as low as 0.111° with four sensors | Synthetic datasets replicating TMR sensor error characteristics |
Table 2: Error Detection Capabilities of Automated Calibration Systems
| System / Test | Parameter Checked | Detection Accuracy / Threshold |
|---|---|---|
| Machine Performance Check (MPC) for Halcyon [67] | MLC Position Accuracy | Within 0.05 mm |
| Absolute Gantry Offset | As small as 0.02° | |
| Beam Symmetry Change | Fails when change exceeds 1.9% | |
| MPC for TrueBeam [68] | Treatment Isocenter Size | 0.31 ± 0.01 mm to 0.42 ± 0.02 mm |
| Output Stability | 0.15 ± 0.07% relative to baseline |
Experimental Protocols
Protocol: Calibration Transfer for Electronic Noses Using Synthetic Urine
This protocol outlines the methodology for transferring a classification model from a "master" Electronic Nose (E-Nose) to a "slave" unit using synthetic urine standards, overcoming the variability of human urine samples [65].
Primary Objective: To enable a slave E-Nose to achieve classification accuracy comparable to a pre-calibrated master device without requiring a full, independent recalibration.
Materials and Reagents:
- Synthetic Urine Recipes: Chemically defined mixtures formulated to mimic the sensor response profiles of real human urine.
- Target Biomarkers: Acetone and 4-heptanone for spiking samples to simulate pathological states [65].
- Sampling System: Consisting of glass bubblers, Nafion membranes for humidity control, Nalophan bags for VOC collection, and mass flow controllers [65].
- E-Nose Setup: Multiple sensor chambers (e.g., custom PEEK chambers) placed in a temperature-controlled oven at 60°C [65].
Procedure:
- Master Model Training:
- Collect headspace from real human urine samples (both pure and spiked with biomarkers) using the sampling system.
- Analyze these samples with the master E-Nose to build a classification model (e.g., PLS-DA).
- Transfer Sample Selection:
- Generate headspace from the reproducible synthetic urine recipes.
- Employ a sample selection strategy (e.g., Kennard-Stone algorithm, DBSCAN-based approach) to identify the most informative subset of synthetic standard measurements for transfer [65].
- Calibration Transfer via Direct Standardization (DS):
- Run the selected synthetic transfer samples on both the master and slave E-Noses.
- Apply the DS algorithm to map the slave device's response space to the master's response space using the data from the transfer samples.
- Apply the transformed model to the slave device.
- Master Model Training:
Validation:
- Validate the transferred model's performance on a separate set of real human urine samples analyzed by the slave device.
- Compare the classification accuracy (e.g., for identifying spiked vs. pure urine) against the master's baseline performance and the slave's performance without CT.
Protocol: Dynamic Calibration for Fault-Tolerant Sensor Arrays
This protocol describes a Self-X architecture that uses multidimensional mapping and synthetic data to dynamically calibrate a redundant sensor array, mitigating faults and misalignments [66].
Primary Objective: To maintain high measurement accuracy in a sensor array even when individual sensors degrade or fail, by leveraging redundancy and dynamic calibration.
Materials and Setup:
- Sensor Array: Homogeneous sensor array (e.g., Tunnel Magnetoresistance (TMR) sensors) with built-in redundancy.
- Fault Injection Platform: An experimental setup capable of introducing controlled mechanical faults (eccentricity, tilt) and electronic signal distortions (offset, amplitude imbalance, phase shift) [66].
- Data Synthesis Tools: Capability to generate synthetic datasets that closely mimic real sensor signals, including characteristic errors, for controlled algorithm benchmarking [66].
Procedure:
- Data Acquisition and Synthesis:
- Collect baseline data from all sensors in the array under normal operating conditions.
- For systematic testing, use the fault injection platform to collect data under various fault conditions. Alternatively, generate realistic synthetic datasets that emulate multiple co-mounted sensors with different fault types.
- Application of Dimensionality Reduction (DR):
- Apply DR algorithms (e.g., Factor Analysis) to the multi-dimensional data from the sensor array.
- The DR process projects the data from the faulty high-dimensional space onto a lower-dimensional, optimized manifold, effectively correcting for systematic errors like offset and amplitude imbalance [66].
- Dynamic Calibration and Data Fusion:
- The calibrated output (e.g., rotation angle, linear position) is extracted from the transformed lower-dimensional space.
- This process runs continuously, allowing the system to self-adapt to changing sensor performance in real-time.
- Data Acquisition and Synthesis:
Validation:
- Benchmark the system's Mean Absolute Error (MAE) under various fault conditions.
- Compare the MAE of the dynamically calibrated array output against the MAE of any single sensor to quantify the performance improvement.
The Scientist's Toolkit
Table 3: Essential Research Reagent Solutions for Sensor Calibration
| Reagent / Material | Function in Experimentation |
|---|---|
| Synthetic Urine Recipes | Provides a chemically defined, reproducible standard that mimics the sensor response of biological samples, enabling reliable calibration transfer [65]. |
| Nafion Membranes | Used as gas dryers to control and reduce humidity in headspace samples, preventing moisture from interfering with metal-oxide semiconductor (MOS) sensor readings [65]. |
| Controlled Fault Injection Platform | Enables the realistic introduction of mechanical and electronic sensor faults, allowing for the development and robust benchmarking of dynamic calibration algorithms [66]. |
| Synthetic Sensor Data | Facilitates the validation of calibration algorithms under controlled and reproducible conditions by emulating the key characteristics and error profiles of real sensor arrays [66]. |
Workflow and System Diagrams
Figure 1: Workflow for E-Nose Calibration Transfer
Figure 2: Self-X Sensor Array Architecture
Validating MPC: Performance Benchmarks and Comparative Analysis
The multi pseudo-calibration (MPC) approach represents a significant advancement for managing time-dependent drift in deeply-embedded chemical sensor arrays used in continuous monitoring applications, such as bioprocess monitoring in the pharmaceutical industry [3]. A critical challenge in this domain is that traditional sensor recalibration using a stable reference is often not feasible without interrupting the ongoing process. The MPC framework addresses this by treating periodic samples with known ground-truth concentrations as "pseudo-calibration" points, thereby enabling continuous calibration without process interruption [3]. However, the development of such sophisticated drift-compensation techniques necessitates an equally sophisticated validation framework to ensure reliable performance assessment under realistic conditions.
The Leave-One-Probe-Out (LOPO) cross-validation technique provides this essential rigorous evaluation framework, specifically designed to test how well calibration models perform on entirely new sensor units—a crucial validation for real-world deployment. This method systematically assesses whether models trained on multiple sensor probes can generalize effectively to new, previously unseen probes, thus testing the robustness and transferability of the calibration approach [3]. Within the context of MPC research, implementing LOPO validation ensures that the drift compensation model does not overfit to the specific characteristics of individual sensor units but instead learns generalizable patterns that apply across the entire sensor array system.
Theoretical Foundation
The Multi Pseudo-Calibration (MPC) Approach
The MPC approach operates on a fundamentally different principle from traditional calibration methods. Instead of requiring dedicated calibration events that interrupt normal operation, it leverages opportunistic calibration points obtained during normal system operation. The mathematical foundation of MPC involves constructing an input vector that concatenates multiple data dimensions: the difference between current sensor measurements and historical pseudo-calibration sample measurements, the ground truth concentration for the pseudo-sample, and the time difference between these measurement events [3].
This approach offers three distinct theoretical advantages that make it particularly suitable for continuous monitoring scenarios:
Non-Linear Drift Modeling: By incorporating time differences and historical measurements, MPC can learn complex, non-linear models of sensor drift that simple linear correction methods might miss [3].
Data Augmentation: The method increases the amount of training data quadratically. Given a training set with N samples, each sample can be paired with any previous sample, resulting in an augmented training set with N(N-1)/2 samples [3].
Variance Reduction: When multiple pseudo-calibration samples are available, MPC can generate predictions relative to each sample and average the results, thereby reducing prediction variance [3].
The MPC framework can be implemented on top of various regression techniques, including partial least squares (PLS), extreme gradient boosting (XGB), and multi-layer perceptrons (MLPs), making it adaptable to different sensor technologies and application requirements [3].
The Critical Need for Rigorous Validation
Sensor arrays, particularly in pharmaceutical applications, face multiple validation challenges that complicate performance assessment:
Unit-to-Unit Variability: Manufacturing tolerances create slight differences between individual sensors, causing models trained on one unit to perform poorly on others [3] [69].
Temporal Drift: Sensors exhibit changing responses over time, creating a moving target for calibration models [3].
Cross-Sensitivity: Sensors often respond to multiple analytes simultaneously, creating complex response patterns that must be deciphered [3] [70].
Traditional random k-fold cross-validation fails to adequately address these challenges because it randomly splits data from the same sensors, potentially leaking information about sensor-specific characteristics between training and testing sets. This leads to overoptimistic performance estimates that don't reflect real-world deployment conditions where models encounter entirely new sensor units.
Leave-One-Probe-Out Cross-Validation Methodology
Core Protocol
The LOPO cross-validation method implements a rigorous testing procedure that mirrors real-world deployment scenarios. The protocol involves the following key steps:
Probe Identification: Identify all distinct sensor probes (physical units) in the dataset. For example, in the referenced bioprocess monitoring study, the dataset contained 4 distinct sensor probes [3].
Data Segmentation: For each probe's dataset, implement a temporal split (typically 75/25) where the first 75% of measurements are designated for training and the last 25% for testing. This approach specifically tests the model's ability to handle temporal drift [3].
Iterative Validation: For each iteration:
- Select one probe to serve as the test set
- Use the remaining probes (with their early-time data) as the training set
- Train the model on the training probes
- Evaluate performance on the held-out test probe using its late-time data [3]
Performance Aggregation: Repeat the process until each probe has served as the test set once, then aggregate performance metrics across all iterations.
Table 1: LOPO Cross-Validation Procedure for a 4-Probe Array
| Iteration | Training Probes | Test Probe | Training Data Segment | Test Data Segment |
|---|---|---|---|---|
| 1 | Probes 1, 2, 3 | Probe 4 | First 75% of measurements | Last 25% of measurements |
| 2 | Probes 1, 2, 4 | Probe 3 | First 75% of measurements | Last 25% of measurements |
| 3 | Probes 1, 3, 4 | Probe 2 | First 75% of measurements | Last 25% of measurements |
| 4 | Probes 2, 3, 4 | Probe 1 | First 75% of measurements | Last 25% of measurements |
Workflow Visualization
LOPO Validation Workflow: The complete iterative process for implementing Leave-One-Probe-Out cross-validation.
Advantages Over Alternative Validation Methods
LOPO cross-validation offers distinct advantages for evaluating sensor array calibration models:
Realistic Generalization Assessment: By testing on completely unseen probes, it accurately measures how well the model will perform when deployed on new sensor units [3].
Drift Resistance Evaluation: The temporal split within each probe's data specifically tests the model's ability to compensate for sensor drift over time [3].
Robustness to Unit Variability: The method ensures the model doesn't rely on probe-specific artifacts by training and testing on different physical units [3] [69].
Alternative methods, such as random k-fold cross-validation or simple train-test splits, often fail to account for the fundamental challenges of sensor array deployment, particularly unit-to-unit variability and long-term drift, leading to inflated performance estimates.
Implementation Protocol for MPC with LOPO Validation
Experimental Setup and Data Collection
Implementing a rigorous LOPO validation for MPC research requires careful experimental design:
Sensor Array Configuration: Deploy multiple sensor probes (recommended minimum of 4) in the target environment. The referenced study used an array of hydrogel-based magneto-resistive sensors for bioprocess monitoring [3].
Data Collection Protocol:
- Collect continuous measurements from all probes over an extended period
- Periodically extract samples for offline analysis to obtain ground-truth concentrations
- Record timestamps for all measurements and pseudo-calibration events [3]
Pseudo-Calibration Points: Identify samples with known ground-truth concentrations to serve as pseudo-calibration points within the MPC framework.
Table 2: Research Reagent Solutions for Sensor Array Evaluation
| Reagent/Category | Function in Evaluation | Application Context |
|---|---|---|
| Hydrogel-based magneto-resistive sensors | Primary sensing element for continuous monitoring | Bioprocess monitoring [3] |
| Colorimetric sensor strips (Mn²⁺, Cu²⁺, Fe²⁺/Fe³⁺) | Testing cross-sensitivity and multi-analyte detection | Water quality analysis [70] |
| Conductive polymer composite sensors | Demonstrating array optimization principles | Chemical vapor detection [69] |
| Reference materials (CRM) | Providing ground-truth concentrations for calibration | Method validation [70] |
| Offline analyzer | Generating reference measurements for pseudo-calibration | Bioprocess monitoring [3] |
Data Preprocessing and Augmentation
The MPC approach requires specific data preprocessing steps to maximize its effectiveness:
Data Normalization: Apply appropriate normalization techniques to balance variations across samples. Research has demonstrated that normalization methods can significantly improve predictive performance in sensor array applications [70].
MPC Data Augmentation: For the training set, implement the MPC augmentation process:
- For each sample in the training data, pair it with all previous pseudo-calibration samples
- Generate augmented input vectors containing:
- Difference between current and pseudo-calibration sensor measurements
- Ground truth concentration of the pseudo-calibration sample
- Time difference between current and pseudo-calibration measurements [3]
Color Space Conversion (for optical sensors): When working with colorimetric sensor arrays, convert sensor images to appropriate color models (RGB, CMYK, HSV, CIELAB) based on the specific application requirements [70].
Model Training and Evaluation
The implementation of MPC with LOPO validation involves these specific training procedures:
Model Selection: Implement the MPC approach on top of multiple regression techniques. The referenced study used Partial Least Squares (PLS), eXtreme Gradient Boosting (XGB), and Multi-Layer Perceptrons (MLP) to demonstrate the approach's flexibility [3].
Training Procedure: For each LOPO iteration:
- Train the model using the augmented training set from the training probes
- Utilize the pseudo-calibration points within the training probes to build the drift compensation model
- Apply the trained model to the held-out test probe
Performance Metrics: Evaluate model performance using appropriate metrics for the application context, including:
- Root Mean Square Error (RMSE)
- Mean Absolute Error (MAE)
- Coefficient of Determination (R²)
Baseline Comparison: Compare MPC performance against appropriate baselines:
- Standard regression without pseudo-calibration
- State-of-the-art drift correction methods, such as Drift Correction Autoencoders (DCAE) [3]
Performance Analysis and Interpretation
Quantitative Evaluation
The rigorous LOPO validation provides meaningful performance metrics that reflect real-world viability:
Table 3: Comparative Performance Analysis of MPC with LOPO Validation
| Regression Method | Validation Approach | Performance Metrics | Key Findings |
|---|---|---|---|
| Partial Least Squares (PLS) | Traditional validation | RMSE: Not reported | Overestimates real-world performance due to data leakage |
| PLS with MPC | LOPO cross-validation | RMSE: Significantly reduced vs. baseline | Demonstrates effective drift compensation on new probes |
| eXtreme Gradient Boosting (XGB) | Traditional validation | RMSE: Not reported | Appears effective but fails to generalize to new units |
| XGB with MPC | LOPO cross-validation | RMSE: Competitive performance across probes | Maintains performance on unseen sensor units |
| Multi-Layer Perceptron (MLP) | Traditional validation | RMSE: Not reported | Potential overfitting to specific sensor characteristics |
| MLP with MPC | LOPO cross-validation | RMSE: Stable across all test probes | Generalizable drift compensation model |
Critical Interpretation of Results
When analyzing LOPO validation results for MPC applications, several key factors require careful consideration:
Performance Stability Across Probes: Consistent performance across all test probes indicates robust generalization, while high variance suggests sensitivity to probe-specific characteristics [3].
Temporal Drift Compensation: The critical test is whether the model maintains accuracy on the late-time data from test probes, demonstrating effective drift compensation on previously unseen sensors [3].
Comparison Baselines: Meaningful evaluation requires comparison against appropriate baselines, including models without drift compensation and state-of-the-art alternative methods [3].
Statistical Significance: Given the typically limited number of probes (often 3-4 in experimental setups), performance differences should be interpreted cautiously, with attention to effect sizes rather than just statistical significance.
Advanced Applications and Methodological Extensions
Integration with Other Calibration Techniques
The LOPO validation framework can be extended to evaluate MPC in conjunction with other calibration methodologies:
Multi-Parameter Calibration: For complex sensor systems, MPC can be combined with multi-parameter calibration approaches that simultaneously address amplitude errors, phase imbalances, and position errors [71].
Hybrid Optimization Strategies: Advanced optimization methods, such as combining genetic algorithms with Newton methods, can enhance the parameter estimation in MPC frameworks, particularly for complex sensor arrays [71].
Cross-Sensitivity Modeling: The LOPO framework can validate MPC's ability to handle cross-sensitive sensors that respond to multiple analytes, a common challenge in chemical sensor arrays [3] [70].
Domain-Specific Adaptations
The MPC approach with LOPO validation can be adapted to various application domains:
Pharmaceutical Bioprocessing: Continuous monitoring of biomarkers and process variables in bioreactors, where sensor recalibration is impossible without process interruption [3].
Environmental Monitoring: Water quality assessment using colorimetric sensor arrays, where the LOPO validation ensures reliable performance across different sensor units and environmental conditions [70].
Medical Diagnostics: Low-conductivity sensing for biomedical applications such as lung water detection, where consistent performance across sensor units is critical for reliable diagnostics [72].
The integration of Leave-One-Probe-Out cross-validation with the multi pseudo-calibration approach establishes a rigorous evaluation framework that accurately assesses sensor array performance under realistic deployment conditions. This methodological combination addresses the critical challenges of sensor drift and unit-to-unit variability that plague continuous monitoring applications in pharmaceutical development and other industries.
By enforcing a strict separation between training and testing sensor units, and specifically evaluating performance on temporally separated data from unseen probes, the LOPO validation framework prevents the overoptimistic performance estimates that result from conventional validation approaches. When coupled with the MPC methodology's ability to leverage opportunistic calibration points during normal operation, this validation approach provides both an effective drift compensation strategy and a truthful assessment of its real-world viability.
For researchers and drug development professionals implementing sensor array technologies, adopting this rigorous validation framework is essential for developing reliable monitoring systems that maintain accuracy across different sensor units and over extended operational periods. The protocol detailed in this document provides a comprehensive roadmap for implementing this validation approach, complete with methodological considerations, implementation guidelines, and performance interpretation criteria.
Within the development of a Multi Pseudo-Calibration (MPC) approach for sensor arrays, establishing robust, non-corrected baselines is a foundational step. This document details the application of standard regression models as baseline benchmarks, providing the essential control against which the performance of advanced drift-compensation strategies like MPC must be evaluated [3]. In chemical sensing applications for sectors such as healthcare and pharmaceutical manufacturing, sensor drift—the gradual, systematic deviation from a calibrated baseline—poses a significant challenge to long-term measurement accuracy [3] [2]. The benchmarking protocols described herein are designed to quantify the performance degradation caused by drift when using standard models, thereby clearly illustrating the necessity and efficacy of dedicated drift-compensation techniques. This establishes the critical control group in the experimental validation of any novel MPC system.
Experimental Principles and Workflow
The core principle of this benchmarking activity is to isolate and measure the effect of sensor drift on prediction accuracy. This is achieved by training and evaluating standard regression models on sensor array data without incorporating any mechanism to correct for temporal changes in the sensor signals [3]. The model operates on the assumption that the relationship between the sensor readings and the target analyte concentration learned during the initial training period remains valid indefinitely, which is often violated in practice due to sensor aging and environmental factors [2].
The following workflow outlines the primary experimental protocol for establishing these baselines, from data collection through to model evaluation.
Research Reagent Solutions and Materials
The experimental setup for benchmarking requires specific computational and data resources. The table below lists the essential components and their functions.
Table 1: Key Research Reagents and Materials for Baseline Benchmarking
| Item Name | Function / Description | Example Specifications / Notes |
|---|---|---|
| Cross-Sensitive Chemical Sensor Array | The core data generation unit; provides multi-dimensional response to analytes [73]. | e.g., 16-element metal-oxide (MOS) array; hydrogel-based magneto-resistive sensors [3] [2]. |
| Standard Regression Model Algorithms | The computational models used to establish baseline performance without drift correction. | Partial Least Squares (PLS), Multi-Layer Perceptron (MLP), Extreme Gradient Boosting (XGB) [3]. |
| Drift-Affected Sensor Dataset | Chronologically ordered data for training and evaluating models under drift conditions. | Public datasets (e.g., Gas Sensor Array Drift) or in-house data from long-term monitoring [2]. |
| Offline Analyzer / Reference Method | Provides ground-truth concentration values for model training and performance validation [3]. | Used to generate "pseudo-calibration" points in MPC; critical for evaluating baseline model accuracy. |
Benchmarking Models and Quantitative Performance
The selection of baseline models should cover a range of algorithmic approaches, from classical linear techniques to more complex non-linear models. This ensures a comprehensive benchmark.
Table 2: Standard Regression Models for Baseline Establishment
| Model | Type | Key Characteristics | Typical Performance Under Drift (RMSE Increase) |
|---|---|---|---|
| Partial Least Squares (PLS) | Linear | Models latent structures, robust to multicollinearity in sensor data. | High susceptibility; significant performance degradation over time [3]. |
| Multi-Layer Perceptron (MLP) | Non-linear Neural Network | Can learn complex, non-linear relationships in sensor responses. | Performance decays as input data distribution shifts due to drift [3]. |
| Extreme Gradient Boosting (XGB) | Ensemble (Non-linear) | High predictive accuracy on complex tabular data. | Similar to MLP; initial high accuracy degrades without explicit drift handling [3]. |
Detailed Experimental Protocol
Sensor Array Configuration and Data Collection
- Sensor Setup: Utilize a cross-sensitive sensor array. The lack of perfect specificity in individual sensors is a key feature that can be leveraged in advanced drift models but is treated as a source of variance in baselines [73].
- Data Acquisition: Collect continuous data from the sensor array over an extended period (e.g., several months). The data should include exposures to target analytes at various concentrations, replicating real-world operating conditions [2]. Each data sample should consist of a feature vector capturing key sensor response metrics.
- Ground Truth Measurement: Periodically, use an offline analyzer to obtain accurate concentration measurements for samples. These serve as the reference for training regression models and for final performance evaluation [3].
Data Preprocessing and Segmentation for Drift Evaluation
- Feature Extraction: For each sensor in the array, compute a set of features from the raw temporal response. Standard features include steady-state amplitude (ΔR), exponential moving averages of the response and recovery phases (e.g.,
ema0.1I_S1), and time constants [2]. - Temporal Splitting: To rigorously evaluate drift, segment the dataset chronologically. A standard protocol is to use the first 75% of the data chronologically for model training and validation, and the final 25% for testing. This tests the model's performance on "future" data affected by drift accumulated after the training period [3].
- Leave-One-Probe-Out Cross-Validation: For a more robust generalizability assessment, implement a leave-one-probe-out method. Data from three sensor probes is used for training, and the fourth is held out for testing, repeating the process for all probes [3].
Baseline Model Training and Evaluation
- Model Training: Train each standard regression model (PLS, MLP, XGB) using only the training subset of the data. The models learn a function
Fthat maps the sensor feature vector at timetto an analyte concentration:Concentration = F(Sensor_Features_t). - Prediction: Use the trained models to predict analyte concentrations on the held-out test set, which contains data from a later time period.
- Performance Quantification: Calculate performance metrics by comparing predictions against the ground truth from the offline analyzer. Key metrics include:
- Root Mean Square Error (RMSE): Quantifies the absolute prediction error.
- Accuracy / R² Score: Measures the proportion of variance explained by the model. Track these metrics over time or across different test batches to visualize performance degradation.
The following diagram illustrates the logical flow of the benchmarking process, highlighting the critical absence of a drift-correction mechanism.
Sensor drift presents a fundamental challenge in the long-term deployment of chemical sensor arrays, leading to a gradual degradation of data quality and predictive accuracy. In the context of pharmaceutical development and bioprocess monitoring, this drift can compromise product quality and process reliability. The multi pseudo-calibration (MPC) approach was developed as a novel strategy for on-line drift compensation, specifically for scenarios where traditional recalibration using reference analytes is impractical, such as in deeply-embedded bioreactor systems [3]. A critical step in validating any new methodology is a rigorous comparison against established state-of-the-art techniques. Among these, the Drift Correction Autoencoder (DCAE) stands out as a prominent and powerful benchmark for handling sensor drift [3]. This application note provides a detailed, head-to-head comparison between the MPC framework and the DCAE method, offering experimental protocols and quantitative analyses to guide researchers and scientists in selecting appropriate drift compensation strategies for their specific applications.
Theoretical Background and Key Methods
Drift Correction Autoencoder (DCAE)
The DCAE is a deep learning-based approach designed to correct for time-dependent drift in sensor data. As an autoencoder, it operates by learning a compressed, latent representation of the input data and then reconstructing a drift-corrected version of the input from this representation. The core assumption is that the latent space captures the underlying, drift-free signal by separating it from the noise and drift components [3]. The model is trained to minimize the reconstruction error, forcing it to learn the essential features of the sensor response that are stable over time.
Multi Pseudo-Calibration (MPC) Approach
The MPC approach offers an alternative strategy that leverages sporadic ground-truth measurements, termed "pseudo-calibration" samples. These samples, obtained through periodic offline analysis (e.g., extracting a sample from a bioreactor for laboratory analysis), provide anchor points for correcting subsequent sensor measurements. The MPC model uses an input vector that concatenates several pieces of information [3]:
- The difference between current sensor measurements and historical pseudo-calibration sample measurements.
- The ground-truth concentration of the pseudo-calibration sample.
- The time difference between the current and pseudo-calibration measurements.
This input structure allows the model to learn a non-linear model of the sensor drift. A significant advantage of MPC is its ability to quadratically increase the effective training data size by pairing each of the N training samples with every previous sample, resulting in N(N-1)/2 training instances [3].
Experimental Comparison: MPC vs. DCAE
Experimental Setup and Dataset
To evaluate the performance of MPC relative to DCAE, a benchmark experimental dataset was collected using an array of hydrogel-based magneto-resistive sensors deployed for bioprocess monitoring [3]. The evaluation employed a leave-one-probe-out cross-validation technique. The dataset from four sensor probes was partitioned such that three probes were used for training and the remaining one for testing; this process was repeated four times. To specifically assess drift compensation performance, the data from each probe was temporally split: the first 75% of measurements were used for training, and the last 25% were reserved for testing, simulating a scenario where the model must predict on data subject to time-dependent drift [3].
Table 1: Key Characteristics of the Experimental Dataset and Evaluation Framework
| Aspect | Description |
|---|---|
| Sensor Technology | Hydrogel-based magneto-resistive sensor array [3] |
| Application Domain | Bioprocess Monitoring [3] |
| Evaluation Method | Leave-one-probe-out Cross-Validation [3] |
| Temporal Split | Train on first 75% of data, test on last 25% to emphasize drift [3] |
| Regression Models for MPC | Partial Least Squares (PLS), Extreme Gradient Boosting (XGB), Multi-Layer Perceptrons (MLP) [3] |
Quantitative Performance Results
The MPC approach was implemented on top of three distinct regression models—PLS, XGB, and MLP—and its performance was compared against two baselines: a) a standard regression model (without pseudo-calibration inputs) and b) the DCAE. The results demonstrated that MPC consistently outperformed the DCAE baseline across different underlying algorithms.
Table 2: Performance Comparison of MPC (across different regression models) versus DCAE
| Model | Key Advantage over DCAE | Quantitative Outcome |
|---|---|---|
| MPC with PLS | Combines drift modeling with a robust, interpretable regression framework. | Superior predictive accuracy on drifted test data [3] |
| MPC with XGB | Leverages powerful non-linear modeling and feature importance. | Outperformed DCAE in handling complex drift patterns [3] |
| MPC with MLP | Utilizes deep learning for drift compensation while incorporating pseudo-calibration logic. | Achieved higher accuracy than DCAE [3] |
| DCAE (Baseline) | Strong, state-of-the-art benchmark for direct drift correction in data [3] | Served as a performance benchmark, which was exceeded by MPC [3] |
Detailed Experimental Protocols
Protocol 1: Implementing the MPC Workflow
The following diagram and protocol outline the steps for applying the MPC approach to a sensor dataset.
Figure 1: The Multi Pseudo-Calibration (MPC) workflow for sensor drift compensation.
Procedure:
- Data Collection & Pseudo-Calibration Sampling: During continuous sensor monitoring, periodically extract physical samples (e.g., from a bioreactor) for offline analysis using a reference method (e.g., HPLC, mass spectrometry) to obtain ground-truth analyte concentrations. Record the timestamp of each sample [3].
- Augmented Dataset Construction: For each data point
iin your training set, create multiple new training instances by pairing it with every previous data pointj(wherej<i) for which a ground-truth pseudo-calibration measurement exists. The input feature vector for each pair is:[S_i - S_j, C_j, t_i - t_j]where:S_i,S_jare the sensor array readings at timesiandj.C_jis the ground-truth concentration from the pseudo-calibration at timej.t_i - t_jis the time difference [3].
- Model Training: Train your chosen regression model (PLS, XGB, or MLP) on the augmented dataset. The target variable is the ground-truth concentration
C_icorresponding to timei. - Inference for Prediction: To predict the concentration for a new sensor reading
S_new, form input vectors relative to all available pseudo-calibration points in memory. Generate a prediction from each vector and compute the final prediction as the average of these individual predictions, thereby reducing variance [3].
Protocol 2: Implementing the DCAE Workflow
This protocol describes the steps for implementing the DCAE method for comparative studies.
Figure 2: The Drift Correction Autoencoder (DCAE) workflow for learning a drift-invariant representation of sensor data.
Procedure:
- Data Preparation: Assemble a training dataset of sensor array readings
Xthat encompasses the expected range of analyte concentrations and a time period long enough to capture typical drift behavior. Normalize the data. - Model Architecture Definition:
- Encoder: A neural network (typically with fully connected or convolutional layers) that maps the input sensor data
Xto a lower-dimensional latent spaceZ. The bottleneck layer forces the network to learn a compressed representation. - Decoder: A second neural network that maps the latent representation
Zback to the original sensor data dimension, outputting the reconstructed, drift-corrected dataX'.
- Encoder: A neural network (typically with fully connected or convolutional layers) that maps the input sensor data
- Model Training: Train the autoencoder in an unsupervised manner by minimizing the reconstruction loss between the original input
Xand the reconstructed outputX'. A common loss function is the Mean Squared Error (MSE):Loss = MSE(X, X'). The training process forces the latent spaceZto capture the most salient, drift-free features of the sensor data. - Drift Correction: For new, drifted sensor data, pass it through the trained encoder to obtain its latent representation, and then through the decoder to obtain the drift-corrected version of the data. This corrected data can then be used with a previously trained calibration model.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key materials and computational tools for drift compensation research
| Item | Function / Description | Relevance in Drift Compensation |
|---|---|---|
| Hydrogel-Based Magneto-Resistive Sensor Array | A specific cross-sensitive sensor technology for monitoring biochemical analytes. | Serves as a primary data acquisition tool; subject to drift, forming the basis for method development and testing [3]. |
| Offline Analyzer (e.g., HPLC, MS) | A high-precision laboratory instrument for determining reference analyte concentrations. | Provides the "ground-truth" data essential for obtaining pseudo-calibration samples in the MPC approach [3]. |
| Pseudo-Calibration Samples | Physical samples extracted during monitoring and analyzed offline to obtain reference concentrations. | Act as calibration anchors within the MPC framework, enabling on-line model updates without process interruption [3]. |
| Python with Scikit-learn, XGBoost, TensorFlow/PyTorch | Standard programming environments and libraries for machine learning and deep learning. | Provides the implementation backbone for regression models (PLS, XGB, MLP) and deep learning models (DCAE) [3]. |
This head-to-head comparison establishes that the Multi Pseudo-Calibration (MPC) approach provides a statistically significant advantage over the state-of-the-art Drift Correction Autoencoder (DCAE) for compensating drift in chemical sensor arrays, particularly in environments like bioprocess monitoring where intermittent ground-truth data is available. The core strength of MPC lies in its intelligent use of pseudo-calibration samples to explicitly model the temporal drift, coupled with a data augmentation strategy that drastically increases the effective training set size. While DCAE remains a powerful unsupervised technique, the quantitative results demonstrate that MPC, when built upon modern regression techniques like XGB or MLP, achieves superior predictive accuracy on data affected by time-varying drift. This makes MPC a highly recommended strategy for researchers and professionals in drug development and pharmaceutical manufacturing seeking to enhance the reliability and longevity of their sensor-based monitoring systems.
This document provides detailed application notes and protocols for analyzing the prediction accuracy and robustness of Multi Pseudo-Calibration (MPC) approaches for sensor arrays. The content is structured to guide researchers, scientists, and drug development professionals in evaluating the long-term performance and reliability of sensor systems. The methodologies outlined herein focus on quantitative metrics, experimental protocols, and visualization tools essential for validating MPC performance in dynamic environments.
Performance Metrics for MPC in Sensor Arrays
The evaluation of sensor array performance under an MPC framework relies on specific quantitative metrics that capture accuracy, robustness, and temporal stability [19]. These metrics are critical for assessing the system's response to parameter perturbations, model uncertainties, and external disturbances over extended operational periods.
Table 1: Core Performance Metrics for Sensor Array MPC Systems
| Metric Category | Specific Metric | Definition/Calculation | Target Value |
|---|---|---|---|
| Tracking Accuracy | Lateral Position Deviation | Vertical distance between actual and reference path [74] | < 0.2 m peak [74] |
| Heading Deviation | Angular difference between actual and reference orientation [74] | < 2 degrees [74] | |
| Statistical Error | Mean Error (ME) | Average of absolute errors over time | Minimize |
| Root Mean Square Error (RMSE) | Square root of the average of squared errors [74] | Minimize | |
| Robustness | Parameter Variation Tolerance | Performance maintenance under model parameter perturbations (e.g., speed, lateral stiffness) [74] | Minimal performance degradation |
| Disturbance Rejection | System's ability to maintain performance despite external disturbances [75] | - |
Experimental Protocols
Protocol 1: Baseline Accuracy and Precision Measurement
This protocol establishes the fundamental accuracy and precision of the sensor array under controlled conditions before introducing perturbations and time-varying factors.
Research Reagent Solutions:
- Reference Calibration Source: A traceable standard for sensor calibration, establishing measurement ground truth [11].
- Data Acquisition System: Hardware and software for collecting sensor array data at high fidelity and synchronized timing [19].
- Environmental Chamber: Enclosure for controlling external conditions (temperature, humidity) to isolate sensor performance [19].
Procedure:
- Setup: Place the sensor array and reference standard in the environmental chamber. Connect all sensors to the data acquisition system.
- Initialization: Stabilize the environmental conditions to a predefined baseline (e.g., 25°C, 50% RH).
- Static Measurement: Expose the array to a constant, known input from the reference standard. Record data from all sensor elements at a specified sampling rate (e.g., 1 kHz) for a period of T = 60 minutes.
- Data Analysis: Calculate the baseline accuracy (mean deviation from reference) and precision (standard deviation of readings) for each sensor element.
Protocol 2: Robustness Evaluation Under Parameter Perturbation
This protocol evaluates the performance of the MPC system when model parameters deviate from their nominal values, simulating real-world uncertainties [74].
Research Reagent Solutions:
- Programmable Signal Simulator: Generates dynamic input signals with precisely controlled variations in amplitude, frequency, and phase.
- Parameter Perturbation Model: Software defining the range and dynamics of parameter variations (e.g., hypercube vertex model for vehicle speed, lateral stiffness) [74].
Procedure:
- Model Definition: Define the nominal system model and the uncertainty set for key parameters (e.g.,
v_nom ± Δv_x,C_nom ± ΔC_f) using a multi-cell hypercube vertex approach [74]. - Input Stimulation: Apply a dynamic reference trajectory (e.g., double lane change, sinusoidal sweep) using the signal simulator.
- Perturbation Injection: Dynamically vary the model parameters within the predefined bounds during the experiment.
- MPC Operation: Run the robust MPC controller, which uses the vertex model and Lyapunov-based constraints to compute control inputs [74].
- Performance Recording: Record the system's outputs and calculate the performance metrics from Table 1 (e.g., lateral deviation, heading error) throughout the perturbation sequence.
Protocol 3: Long-Term Stability and Drift Assessment
This protocol characterizes the temporal degradation of prediction accuracy and the effectiveness of the MPC's self-calibration over time.
Research Reagent Solutions:
- Aging Test Fixture: Apparatus for subjecting the sensor array to accelerated life testing conditions (e.g., thermal cycling, continuous operation).
- In-Situ Reference Sensor: A high-accuracy, low-drift sensor co-located with the array to provide a continuous performance benchmark [11].
Procedure:
- Deployment: Install the sensor array and the in-situ reference sensor in the aging test fixture.
- Accelerated Aging: Subject the system to accelerated stress conditions (e.g., thermal cycles from -10°C to 60°C) for a defined period (e.g., 1,000 hours).
- Intermittent Testing: At regular intervals (e.g., every 100 hours), pause the aging and execute Protocol 1 under standard conditions.
- Drift Quantification: For each test interval, compute the drift as the change in mean error and RMSE relative to the baseline (T=0 hours).
- MPC Re-calibration: Activate the multi-source self-calibration routine within the MPC framework to correct for observed drift and re-assess performance [11].
Workflow and System Visualization
MPC for Sensor Arrays Workflow
The following diagram illustrates the core operational and calibration workflow for a robust MPC system applied to sensor arrays.
Robust MPC Structure for Uncertainty Handling
This diagram details the internal structure of the Robust MPC block, highlighting its dual-layer optimization for handling model uncertainty.
This application note details the experimental results and protocols for developing hydrogel-based magneto-resistive sensor arrays. These sensors synergize the biocompatibility, flexibility, and stimulus-responsiveness of hydrogels with the high sensitivity and electronic readout capabilities of magnetoresistive transducers [76] [77]. The presented data and methodologies are framed within the multi pseudo-calibration (MPC) approach, which is critical for enhancing measurement accuracy, compensating for environmental fluctuations, and ensuring reliable performance in complex biological matrices [6]. We provide a comprehensive toolkit for researchers, including summarized quantitative data, detailed fabrication and sensing protocols, and a visualization of the integrated signaling pathway.
Experimental Datasets
The performance of hydrogel-based magneto-resistive sensors is evaluated through key metrics including sensitivity, dynamic range, and stability. The following tables consolidate experimental data from relevant studies.
Table 1: Performance Metrics of Hydrogel-Based and Related Magnetic Sensors.
| Sensor Type / System | Key Performance Metric | Value | Experimental Conditions | Reference |
|---|---|---|---|---|
| AMF-Mediated Printable NiFe Sensor | Sensitivity | 35.7 T⁻¹ | At 0.086 mT; AMF at 50 Hz | [78] |
| AMF-Mediated Printable NiFe Sensor | Figure of Merit (FoM) | 4.1 × 10⁵ T⁻² | FoM = (Sensitivity)² / Noise | [78] |
| AMF-Mediated Printable NiFe Sensor | Noise | 19 µΩ/√Hz | --- | [78] |
| AMF-Mediated Printable NiFe Sensor | Resolution | 36 nT | --- | [78] |
| Soft Bimodal Hydrogel Array (Strain) | Gauge Factor (GF) | 1.638 (Stretch), -0.726 (Compress) | Strain sensing mode | [79] |
| Soft Bimodal Hydrogel Array (Pressure) | Sensitivity | 0.267 kPa⁻¹ (Below 3.45 kPa) | Pressure sensing mode | [79] |
| GMR SV Biosensor (with MIA) | Detection Limit | 10 fM | Secretory leukocyte peptidase inhibitor (SLPI) biomarker | [77] |
Table 2: Multi-Parameter Sensing and Self-Healing Performance.
| Characteristic | Sensor System | Result | Implication for MPC |
|---|---|---|---|
| Multimodal Sensing | Soft Bimodal Hydrogel Array | Simultaneous strain and pressure measurement [79] | Provides complementary data streams for cross-validation. |
| Self-Healing Efficiency | AMF-Mediated NiFe Sensor | 100% performance recovery over 4 cycles in seconds [78] | Maintains sensor array integrity and calibration stability. |
| Anti-Interference | MSCD Electrochemical Strategy | Relative errors ≤ 8.3% against pH/temperature fluctuations [6] | Demonstrates principle of using algorithmic calibration to offset environmental noise. |
Experimental Protocols
Fabrication of Conductive Hydrogel for Sensing
This protocol describes the synthesis of a highly stretchable and transparent ionic conductive hydrogel, adapted for sensor array fabrication [79].
Materials:
- Monomer: Acrylamide (AAm)
- Crosslinker: N,N-methylenebisacrylamide (MBAA)
- Initiator: Ammonium Persulfate (AP)
- Catalyst: N,N,N,N-Tetramethylethylenediamine (TEMED)
- Conductive Salt: Sodium Chloride (NaCl)
- Solvent: Deionized (DI) Water
Procedure:
- Solution Preparation: Dissolve 15.62 g of AAm monomer and 16.029 g of NaCl in 100 mL of DI water under constant agitation.
- Initiation and Crosslinking: To the prepared solution, add 0.17 g of AP initiator and 0.06 g of MBAA crosslinker.
- Catalyzation: Add 0.25 g of TEMED catalyst to the mixture to enhance conductivity and increase the polymerization reaction rate.
- Gelation and Curing: Allow the solution to crosslink for 60 minutes at room temperature until a monolithic hydrogel forms.
- Equilibration: Peel the resulting hydrogel from the mold and immerse it in a NaCl solution of the same concentration for 24 hours to absorb water and reach a new state of equilibrium.
- Integration: The cured hydrogel is then integrated with magnetoresistive elements, either by embedding magnetic microparticles (e.g., Ni₈₁Fe₁₉) during synthesis for active sensing [78] or by coupling with a separate Giant Magnetoresistive Spin-Valve (GMR SV) sensor chip in a hybrid structure for biomarker detection [77].
Magnetic Immunoassay (MIA) for Biomarker Detection
This protocol details the steps for using a GMR SV biosensor functionalized with a hydrogel interface for the ultrasensitive detection of protein biomarkers [77].
Materials:
- GMR SV Sensor Array
- Capture Antibody (specific to target biomarker)
- Sample (serum, buffer, etc.)
- Biotinylated Detection Antibody
- Streptavidin-functionalized Magnetic Nanotags (MNTs)
- Wash Buffers
Procedure:
- Functionalization: Immobilize a capture antibody specific to the target biomarker on the sensor surface via covalent chemistry. Different capture antibodies can be immobilized on individual sensors within an array for multiplexing.
- Sample Incubation: Introduce the sample containing the biomarker onto the sensor array. Incubate to allow the target biomarker to bind to the capture antibody. Wash away unbound biomarkers.
- Detection Antibody Incubation: Introduce a biotinylated detection antibody that binds to a different epitope on the captured biomarker. Incubate and wash away unbound detection antibodies.
- Magnetic Labeling: Introduce streptavidin-functionalized MNTs. These will bind to the biotin on the detection antibodies, completing the sandwich assay.
- Measurement and Readout: Apply an external magnetic field to magnetize the MNTs. The stray field from the bound MNTs alters the resistance of the underlying GMR SV sensor, which is measured by the integrated readout electronics. The resistance change is proportional to the number of bound MNTs and, hence, the biomarker concentration.
Multi Pseudo-Calibration (MPC) Data Acquisition Protocol
This protocol outlines the calibration and measurement strategy to offset the effects of co-existing reagents and environmental fluctuations, inspired by the MSCD strategy [6].
- Procedure:
- Multi-Parameter Baseline Establishment: Record baseline signals from all sensors in the array (including those functionalized for different targets and/or reference sensors) in a controlled buffer solution.
- Standard Additions: For a given sample, perform a series of measurements with the sample, a diluted version of the sample, and the sample with a known amount of analyte added (standard addition).
- Environmental Monitoring: Simultaneously, record data from reference sensors that are sensitive to environmental interferents (e.g., pH, temperature) but not the primary analyte.
- Data Processing with Linear Regression: Develop a linear regression model that uses the data from the series of measurements and the reference sensors. The model correlates the output signals from the active sensors with the known changes in analyte concentration, while simultaneously subtracting the signal drift contributed by the environmental fluctuations measured by the reference sensors.
- Concentration Calculation: The calibrated model is used to calculate the accurate concentration of the target analytes in the unknown sample, effectively offsetting batch-to-batch sensor variations and environmental noise [6].
Signaling Pathways and Workflows
The following diagram illustrates the integrated working principle of a hydrogel-based magneto-resistive sensor array and its data processing within the MPC framework.
Diagram Title: Hydrogel-Magnetoresistive Sensor and MPC Workflow.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Hydrogel-Based Magneto-Resistive Sensor Development.
| Item Name | Function / Role | Specific Example |
|---|---|---|
| Polyvinyl Alcohol (PVA) | Synthetic polymer forming the hydrogel backbone; provides biocompatibility and mechanical stability [80]. | PVA (MW=105,000–110,000; 99% alcoholysis) [80]. |
| Ionic Salts (e.g., NaCl) | Imparts ionic conductivity to the hydrogel, enabling piezoresistive sensing or acting as an electrolyte [79]. | Sodium Chloride (NaCl) [79]. |
| Magnetic Nanotags (MNTs) | Superparamagnetic labels for biomarker detection; their stray field is detected by the GMR sensor [77]. | ~50 nm dextran-coated particles with superparamagnetic iron oxide cores [77]. |
| GMR Spin-Valve (SV) Sensors | The core magnetoresistive transducer; converts changes in magnetic field into measurable resistance changes [77]. | Thin-film stack (e.g., PtMn/CoFe/Ru/CoFe/Cu/CoFe) passivated with oxide [77]. |
| Alternating Magnetic Field (AMF) Generator | Used to actively structure magnetic filler particles within the hydrogel composite, enhancing sensitivity and enabling self-healing [78]. | System generating AMF (e.g., 50 Hz, <130 mT) [78]. |
| Crosslinking Agents | Forms the 3D network structure of the hydrogel, determining its mechanical strength and swelling behavior. | N,N-methylenebisacrylamide (MBAA) [79] or dynamic boron/oxygen dative bonds in polyborosiloxane (PBS) [78]. |
Sensor arrays are pivotal in continuous monitoring applications within pharmaceutical bioprocessing and medical diagnostics [3]. However, their reliability is perpetually challenged by cross-sensitivity, the tendency of a sensor to respond to multiple analytes, and sensor drift, the gradual, systematic deviation of sensor responses over time [2] [44]. These phenomena can lead to inaccurate quantification of target analytes, potentially compromising process control and product quality.
The multi pseudo-calibration (MPC) approach offers a robust framework for online calibration, addressing a critical limitation of traditional methods: the impracticality of periodic recalibration in deeply-embedded systems like bioreactors [3]. This protocol details the integration of synthetic data validation within an MPC framework to proactively control for cross-sensitivity and quantify the impact of drift severity, thereby ensuring long-term analytical accuracy.
Theoretical Foundation and the MPC Framework
The MPC approach is predicated on using historical sensor measurements with known ground-truth concentrations as "pseudo-calibration" points [3]. This method constructs an augmented input vector for a regression model, incorporating the difference between current and past sensor measurements, the ground-truth concentration of the pseudo-sample, and the time difference. The core advantage of MPC is its ability to learn a non-linear model of the sensor drift and quadratically increase the effective training data by pairing all available samples [3].
Synthetic data, which replicates the statistical properties and patterns of real-world data without containing actual measurements, serves as a critical tool for stress-testing the MPC pipeline [81]. By generating data that simulates various degrees of cross-sensitivity and drift severity, researchers can preemptively identify failure modes and establish the operational boundaries of their calibration system.
The Validation Trinity for Synthetic Data
For synthetic data to be trustworthy, its validation must rest on three interdependent pillars [81]:
- Fidelity: The synthetic data must statistically resemble the real-world data in terms of distributions, correlations, and patterns.
- Utility: A model trained on synthetic data must perform effectively when applied to real-world tasks (e.g., concentration prediction).
- Privacy: The data must be free of identifiable information from the original dataset, ensuring compliance with regulations.
These dimensions exist in tension; maximizing one can impact another. The goal is a balance tailored to the specific use case's risk tolerance and requirements [81].
Experimental Protocols
Protocol 1: Generating and Validating Synthetic Sensor Data
This protocol outlines the creation of a realistic synthetic dataset that incorporates controllable cross-sensitivity and drift parameters.
1. Objective: To generate a benchmark synthetic dataset for evaluating the MPC approach under defined conditions of cross-sensitivity and drift.
2. Reagent & Computational Solutions:
- Real-World Sensor Dataset: A foundational dataset like the Gas Sensor Array Drift (GSAD) dataset, which contains long-term recordings from 16 metal-oxide sensors exposed to six gases over three years [2].
- Generative Model: Machine learning models such as Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs) trained on the foundational dataset.
- Simulation Software: Platforms like MATLAB or Python with libraries (NumPy, SciPy) for implementing mathematical models of sensor behavior.
3. Procedure:
- Step 1: Model Cross-Sensitivity. For a sensor array with
msensors andnanalytes, define a cross-sensitivity matrix,C, of dimensionsm x n. Each elementC_ijrepresents the response magnitude of sensorito analytej. This creates a fingerprint for each analyte [44]. - Step 2: Model Drift Dynamics. Implement a drift function for each sensor. A common approach is to use a combination of linear and exponential components:
D_i(t) = a_i * t + b_i * (1 - exp(-c_i * t))whereD_i(t)is the total drift of sensoriat timet, anda_i,b_i,c_iare parameters controlling drift severity and dynamics [2]. - Step 3: Data Generation. For a target analyte concentration profile, compute the raw sensor response by combining the cross-sensitive response (using matrix
C) and the drift functionD(t). Add Gaussian noise to simulate experimental variability. - Step 4: Validation of Synthetic Data.
- Statistical Comparisons: Use the Kolmogorov–Smirnov test and Jensen-Shannon divergence to compare distributions of synthetic and real features [81].
- Utility Testing: Employ a "Train on Synthetic, Test on Real" (TSTR) paradigm. Train a concentration prediction model on the synthetic data and evaluate its performance (e.g., using Mean Absolute Error) on a held-out set of real data [81].
- Expert Review: Subject matter experts should qualitatively review the data to identify patterns or outliers that defy domain knowledge, such as physiologically implausible analyte combinations [81].
Protocol 2: Integrating Synthetic Data into the MPC Workflow
This protocol describes leveraging synthetic data to optimize and validate the MPC system before deployment.
1. Objective: To use synthetic data for benchmarking MPC performance against varying drift severity and for generating abundant training data for the underlying regression models.
2. Procedure:
- Step 1: Benchmarking. Generate multiple synthetic datasets with escalating drift severity parameters. Evaluate the performance (e.g., prediction error) of the MPC system on each dataset to establish its operational limits.
- Step 2: Data Augmentation. Use the validated synthetic data generator to create a large, diverse dataset of pseudo-calibration points. This augmented dataset is used to train the MPC's regression model (e.g., PLS, XGBoost, or MLP), improving its robustness to real-world variation [3].
- Step 3: Continuous Validation. As real operational data is collected, continuously monitor for data drift—changes in the input data distribution. Techniques like domain-adversarial learning can detect such shifts, triggering the need to update the synthetic data generation model or retrain the MPC system [2] [82].
The following diagram illustrates the integrated experimental workflow, from synthetic data generation to MPC deployment and continuous validation.
Diagram 1: Integrated workflow for synthetic data validation and MPC deployment. The process creates a closed-loop system where production monitoring can trigger updates to the synthetic data models.
Quantitative Benchmarks and Reagent Solutions
To ensure meaningful experimentation, the following tables summarize key performance benchmarks and essential research components.
Table 1: Performance Benchmarks for Drift Compensation Methods on the GSAD Dataset This table compiles reported performance of various algorithms on the benchmark GSAD dataset, providing a reference for expected outcomes [3] [2].
| Method / Model | Reported Metric (Accuracy) | Key Advantage | Drift Severity Tested |
|---|---|---|---|
| Incremental Domain-Adversarial Network (IDAN) | Significant enhancement over baselines | Integrates domain-adversarial learning with incremental adaptation [2]. | Severe |
| Multi Pseudo-Calibration (MPC) + MLP | Strong performance in bioprocess monitoring | Learns non-linear drift model; uses available ground-truth [3]. | Moderate to Severe |
| Multi Pseudo-Calibration (MPC) + XGBoost | Strong performance in bioprocess monitoring | Robust to non-linearities; handles augmented training data well [3]. | Moderate to Severe |
| Drift Correction Autoencoder (DCAE) | Used as a strong baseline | A state-of-the-art method for comparison [3]. | Moderate |
| Iterative Random Forest Correction | Enhances data integrity in real-time | Corrects abnormal sensor responses before prediction [2]. | Mild to Moderate |
Table 2: Research Reagent Solutions for Sensor Array and Synthetic Data Research This table lists critical components for establishing a research pipeline in this field.
| Item | Function / Purpose | Example & Notes |
|---|---|---|
| Commercial E-Nose System | Provides a platform for collecting real sensor array data under controlled conditions. | Systems from manufacturers like Smelldect GmbH; often include 62+ metal-oxide sensors [83]. |
| Benchmark Drift Dataset | Serves as a standard for developing and comparing drift compensation algorithms. | The Gas Sensor Array Drift (GSAD) Dataset is the definitive benchmark for long-term drift studies [2]. |
| Generic Multisensor Integration Strategy (GMIS) | A framework for pre-analyzing the potential performance of online sensor calibration. | Used in Kalman filtering to assess observability of sensor errors before data collection [42]. |
| Domain Adaptation Algorithms | Enable models to maintain performance when data distributions shift over time (drift). | Incremental Domain-Adversarial Network (IDAN) is a leading-edge example [2]. |
| Data Engine Platform | Centralizes workflows for synthetic data generation, curation, and quality assurance. | Platforms like Maxim AI's Data Engine facilitate generation, deduplication, and drift-aware curation [84]. |
The integration of rigorously validated synthetic data within the multi pseudo-calibration framework presents a powerful methodology for bolstering the reliability of sensor arrays. By systematically simulating and controlling for cross-sensitivity and drift severity in silico, researchers can de-risk the deployment of MPC systems in critical applications such as bioprocess monitoring and drug development. This proactive validation strategy, grounded in the principles of fidelity, utility, and privacy, ensures that calibration models are robust, adaptive, and capable of sustaining high performance throughout the sensor's operational lifespan.
Conclusion
The Multi Pseudo-Calibration (MPC) approach represents a significant advancement for enabling reliable, long-term sensor array operation in critical biomedical environments like bioprocess monitoring and drug development. By systematically leveraging historical ground-truth measurements as pseudo-calibration points, MPC effectively models and compensates for complex, non-linear sensor drift without interrupting ongoing processes. Its integration with powerful regression models and its inherent data augmentation capability provide a robust framework that has demonstrated superior performance against standard and state-of-the-art drift correction methods. Future directions for MPC include its adaptation to a wider range of sensing modalities, such as electronic noses for disease diagnostics via urine headspace analysis, full automation for closed-loop control systems, and exploration in emerging clinical applications like continuous biomarker monitoring. The principles of MPC offer a versatile and powerful tool to enhance data integrity and decision-making across the biomedical field.
References
- 1. Sensor Noise & Drift: Labelling in Imperfect Conditions [https://skillwisor.com/2025/07/11/sensor-noise-drift-labelling-in-imperfect-conditions/]
- 2. Real-Time Correction and Long-Term Drift Compensation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12471586/]
- 3. On-line drift compensation for continuous monitoring with ... [https://www.sciencedirect.com/science/article/abs/pii/S0925400522007225]
- 4. Recent Advances in Micro- and Nano-Enhanced Intravascular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12349352/]
- 5. TinyML-Based Real-Time Drift Compensation for Gas ... [https://www.mdpi.com/2227-9040/13/7/223]
- 6. Simultaneously calibrate and detect multiple analytes to ... [https://pubmed.ncbi.nlm.nih.gov/41135991/]
- 7. Experimental validation of model-free predictive control ... [https://www.nature.com/articles/s41598-024-77846-0]
- 8. A framework for realisable data-driven active flow control ... [https://arxiv.org/html/2510.11600v1]
- 9. Investigation into the Performance Enhancement and ... [https://www.mdpi.com/2227-7390/13/15/2341]
- 10. DriftGAN: Using historical data for Unsupervised Recurring ... [https://arxiv.org/html/2407.06543]
- 11. [1003.1892] Multisource Self-calibration for Sensor Arrays [https://arxiv.org/abs/1003.1892]
- 12. Time series analysis and prediction of nonlinear systems ... [https://www.sciencedirect.com/science/article/abs/pii/S0020025521004357]
- 13. Challenges and Opportunities in Calibrating Low-Cost ... [https://www.mdpi.com/1424-8220/24/11/3650]
- 14. Evaluating the Performance of Using Low-Cost Sensors to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9355096/]
- 15. Smart porous-framework sensor arrays: Design principles ... [https://www.sciencedirect.com/science/article/abs/pii/S0010854525008768]
- 16. A method of gas sensor drift compensation based on ... [https://www.nature.com/articles/s41598-023-39246-8]
- 17. Adaptive machine learning strategies for network ... [https://www.sciencedirect.com/science/article/abs/pii/S0167865520301549]
- 18. Low-Cost CO Sensor Calibration Using One Dimensional ... [https://www.mdpi.com/1424-8220/23/2/854]
- 19. Sensor Arrays: A Comprehensive Systematic Review - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC12390142/]
- 20. Analyzing the Impact of Time Synchronization in Sensor ... [https://arxiv.org/html/2209.01136v2]
- 21. A Guide to Time-Series Sensor Data Classification Using ... [https://medium.com/data-science/a-guide-to-time-series-sensor-data-classification-using-uci-har-data-b7ac4f6ad251]
- 22. Derivation of Hyperspectral Profiles for Global Extended Pseudo Invariant Calibration Sites (EPICS) and Their Application in Satellite Sensor Cross-Calibration [https://www.mdpi.com/2072-4292/17/2/216]
- 23. DATA SENSOR FUSION IN DIGITAL TWIN TECHNOLOGY ... [https://arxiv.org/html/2502.08874]
- 24. Locally-weighted-RoBoost-PLS: a multivariate calibration ... [https://www.sciencedirect.com/science/article/pii/S0003267025005616]
- 25. In-field Calibration of Low-Cost Sensors through XGBoost [https://arxiv.org/html/2506.15840v1]
- 26. Application of RR-XGBoost combined model in data ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8329182/]
- 27. application to color-changing biochemical assays - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC11744771/]
- 28. Multiple Outputs — xgboost 3.1.1 documentation [https://xgboost.readthedocs.io/en/stable/tutorials/multioutput.html]
- 29. Model Predictive Control for Bioprocess Forecasting and ... [https://www.bioprocessintl.com/process-monitoring-and-controls/model-predictive-control-for-bioprocess-forecasting-and-optimization]
- 30. Improving Bioprocess Monitoring and Control with ... [https://www.sigmaaldrich.com/US/en/technical-documents/technical-article/improving-bioprocess-monitoring-and-control-with-multivariate-data-analysis?srsltid=AfmBOoqMsfoN1y8AwfcPor_GBLdgvB2sQLE_OXJ29iKx64-EvF9vKf_t]
- 31. Bioprocess Monitoring and Control (Off-Line, At-Line, On- ... [https://www.hamiltoncompany.com/knowledge-base/article/bioprocess-monitoring-and-control?srsltid=AfmBOoppPB1u3yfVt38f8KxENilqTCZyxuKCifPRvLzTQ6A0G6oVhKvB]
- 32. Bioprocess Monitoring: A Moving Horizon Estimation ... [https://www.sciencedirect.com/science/article/abs/pii/S2405896322008497]
- 33. Bioprocess Monitoring and Control Technologies [https://www.nature.com/research-intelligence/nri-topic-summaries/bioprocess-monitoring-and-control-technologies-micro-1944]
- 34. How Extracellular Uses TDengine's Virtual Tables to ... [https://tdengine.com/how-extracellular-uses-tdengines-virtual-tables-to-streamline-bioprocess-monitoring/]
- 35. Real-Time Monitoring to Large Data Modeling for ... [https://community.jmp.com/t5/Abstracts/Real-Time-Monitoring-to-Large-Data-Modeling-for-Bioprocessing/ev-p/776181]
- 36. An Edge-Deployable Multi-Modal Nano-Sensor Array ... [https://www.mdpi.com/2073-4441/17/14/2065]
- 37. Bulk and Surface Acoustic Wave Sensor Arrays for Multi- ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6960530/]
- 38. Future prospects, challenges and opportunities in detecting ... [https://www.sciencedirect.com/science/article/abs/pii/S2214714425010645]
- 39. Physics-informed calibration model for enhanced accuracy ... [https://www.sciencedirect.com/science/article/abs/pii/S0957417425009352]
- 40. Integrating probability and big non-probability samples ... [https://link.springer.com/article/10.1007/s10260-023-00740-y]
- 41. Multiscale calibration networks with pseudo label for ... [https://www.sciencedirect.com/science/article/abs/pii/S1474034625005877]
- 42. Analytical Framework for Online Calibration of Sensor ... [https://www.mdpi.com/1424-8220/25/10/3239]
- 43. Understanding Cross Sensitivities Can Help to Keep ... [https://www.indsci.com/en/blog/understanding-cross-sensitivities-can-help-to-keep-workers-safer]
- 44. Overcoming the Limits of Cross-Sensitivity: Pattern ... [https://link.springer.com/article/10.1007/s40820-024-01489-z]
- 45. Sensor Cross Sensitivity [https://gastech.com/Sensorcrosssensitivity]
- 46. Gas Sensor Cross Sensitivity (2026 Ultimate Tables) [https://www.forensicsdetectors.com/blogs/articles/gas-sensor-cross-sensitivity-ultimate-list?srsltid=AfmBOoo05CYT48f7vJLBFF235JmmQ9PWX1h_8MJtUAeWjuiM3jcdHvjN]
- 47. Deployment, Calibration, and Cross-Validation of Low-Cost ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8234435/]
- 48. Electrochemical Gas Sensor Cross Interference Table [https://www.indsci.com/en/blog/electrochemical-sensor-cross-interference-table]
- 49. ZnO Sensor Array and Convolutional Neural Networks [https://www.nature.com/articles/s41598-025-26084-z]
- 50. ML-AMPSIT: Machine Learning-based Automated Multi ... - GMD [https://gmd.copernicus.org/articles/18/433/2025/]
- 51. Generative Artificial Intelligence for Synthetic Spectral Data ... [https://www.mdpi.com/1424-8220/25/13/4114]
- 52. ACC 2025 Program | Tuesday July 8, 2025 - PaperPlaza [https://css.paperplaza.net/conferences/conferences/ACC25/program/ACC25_ContentListWeb_1.html]
- 53. IEEE SMC 2025 Program | Tuesday October 7 ... - PaperCept [https://conf.papercept.net/conferences/conferences/SMC25/program/SMC25_ContentListWeb_3.html]
- 54. 9.2 Principal Components Regression and Partial Least Square [https://scientistcafe.com/ids/principal-components-regression-and-partial-least-square]
- 55. 16 Partial Least Squares Regression | All Models Are Wrong [https://allmodelsarewrong.github.io/pls.html]
- 56. Parameter Tuning [https://mixomics.org/parameter-tuning/]
- 57. Notes on Parameter Tuning — xgboost 3.1.1 documentation [https://xgboost.readthedocs.io/en/stable/tutorials/param_tuning.html]
- 58. Optimizing XGBoost: A Guide to Hyperparameter Tuning [https://medium.com/@rithpansanga/optimizing-xgboost-a-guide-to-hyperparameter-tuning-77b6e48e289d]
- 59. The Ultimate Guide to XGBoost Parameter Tuning [https://randomrealizations.com/posts/xgboost-parameter-tuning-with-optuna/]
- 60. Multilayer Perceptron and its Hyperparameter Tuning [https://medium.com/@vijaikdasari/multilayer-perceptron-and-its-hyperparameter-tuning-deedfbca2d1b]
- 61. Tuning MLPRegressor hyper parameters - python [https://stackoverflow.com/questions/61163759/tuning-mlpregressor-hyper-parameters]
- 62. Hyperparameter Tuning [https://www.geeksforgeeks.org/machine-learning/hyperparameter-tuning/]
- 63. Deep learning framework for sensor array precision and ... [https://www.nature.com/articles/s41598-023-38290-8]
- 64. Collaborative Filtering to Predict Sensor Array Values in Large ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7472609/]
- 65. Development of a Calibration Transfer Methodology and ... [https://www.mdpi.com/2227-9040/13/11/395]
- 66. Enhancing Reliability in Redundant Homogeneous Sensor ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12252083/]
- 67. Independent validation of machine performance check for the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6123154/]
- 68. Evaluation of the Machine Performance Check application for ... [https://ro-journal.biomedcentral.com/articles/10.1186/s13014-015-0381-0]
- 69. Optimum design of sensor arrays via simulation-based ... [https://www.sciencedirect.com/science/article/abs/pii/S0925400511001766]
- 70. Investigation into the predictive performance of colorimetric ... [https://jast-journal.springeropen.com/articles/10.1186/s40543-021-00271-9]
- 71. A Multi-Parameter Calibration Method Based on the ... [https://www.mdpi.com/2072-4292/16/24/4677]
- 72. Design of a Remote, Multi-Range Conductivity Sensor - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC10747276/]
- 73. Sensor Array - an overview [https://www.sciencedirect.com/topics/engineering/sensor-array]
- 74. Improved Robust Model Predictive Trajectory Tracking ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12608895/]
- 75. Precision Synchronous Control of Multiple Motion Systems... [https://www.ieee-jas.net/en/article/doi/10.1109/JAS.2025.125222]
- 76. Hydrogel-based sensors for multimodal health monitoring [https://pubs.rsc.org/en/content/articlehtml/2025/nr/d5nr03553h?page=search]
- 77. A 256 pixel magnetoresistive biosensor microarray in 0.18 ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3993911/]
- 78. Self-healable printed magnetic field sensors using ... [https://www.nature.com/articles/s41467-022-34235-3]
- 79. Soft Bimodal Sensor Array Based on Conductive Hydrogel ... [https://www.mdpi.com/1424-8220/20/6/1641]
- 80. Designing high performance hydrogel sensor for real-time ... [https://www.sciencedirect.com/science/article/abs/pii/S0026265X24013845]
- 81. Synthetic Data Validation: Methods & Best Practices [https://www.qualtrics.com/articles/strategy-research/synthetic-data-validation/]
- 82. Empirical data drift detection experiments on real-world ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10904813/]
- 83. Long-term drift behavior in metal oxide gas sensor arrays [https://www.nature.com/articles/s41597-025-05993-8]
- 84. Synthetic Data for RAG: Safe Generation, Deduplication, ... [https://dev.to/kuldeep_paul/synthetic-data-for-rag-safe-generation-deduplication-and-drift-aware-curation-in-2025-3298]